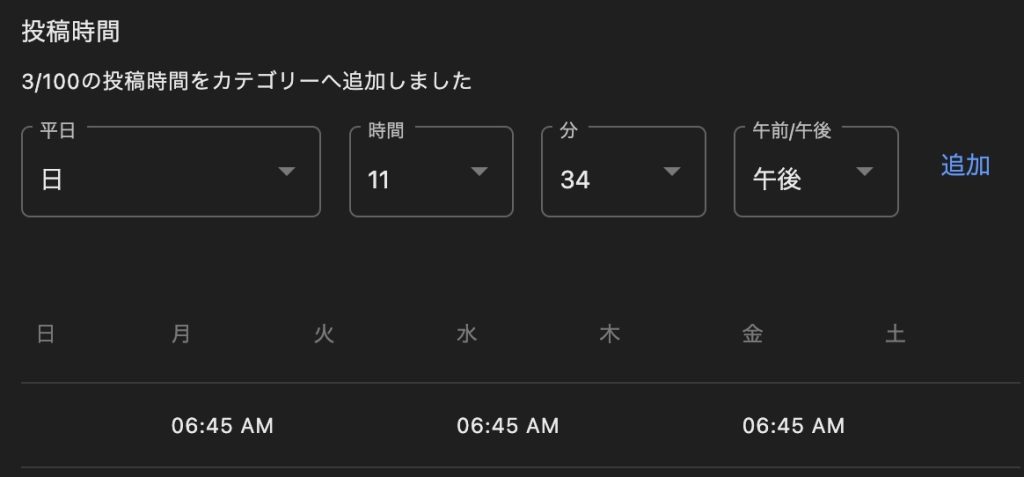
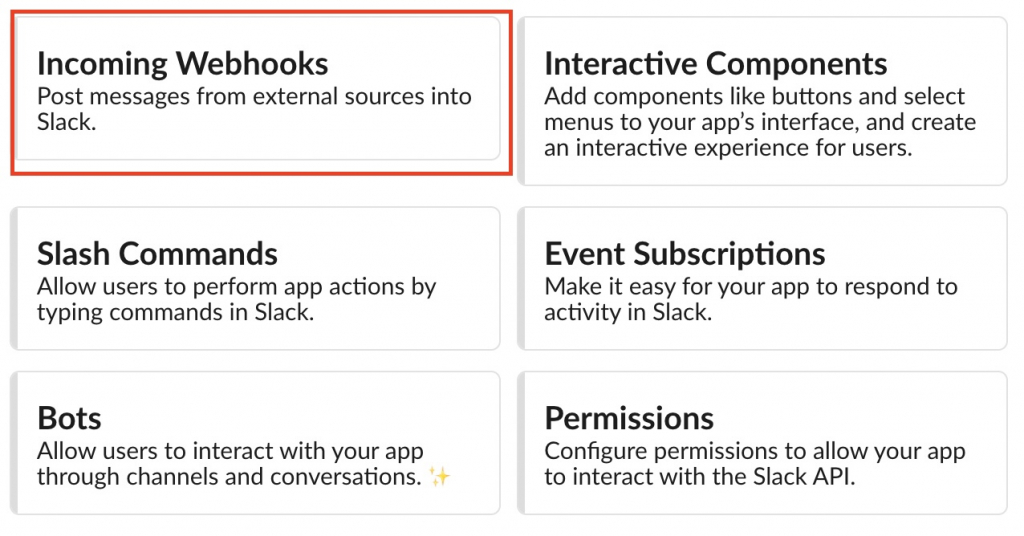
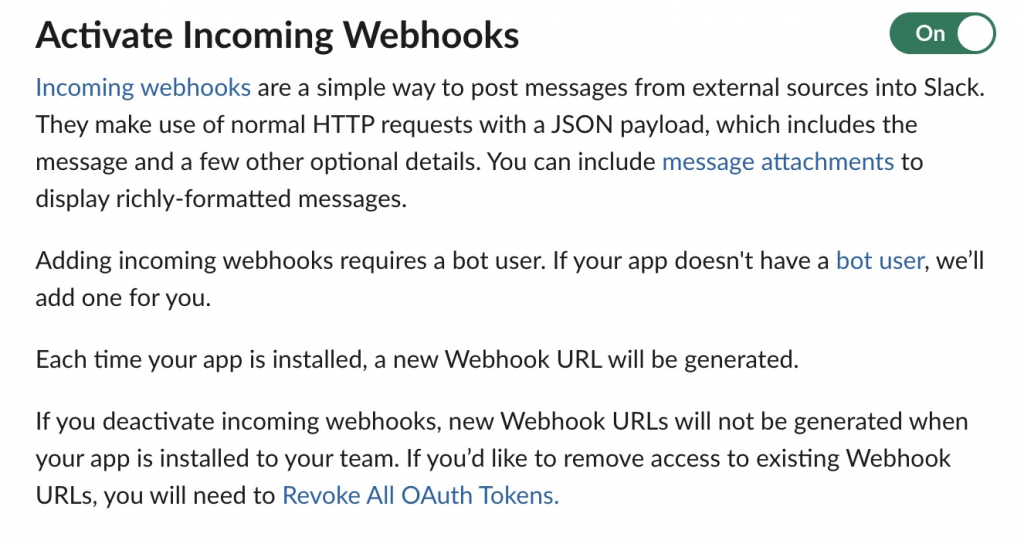
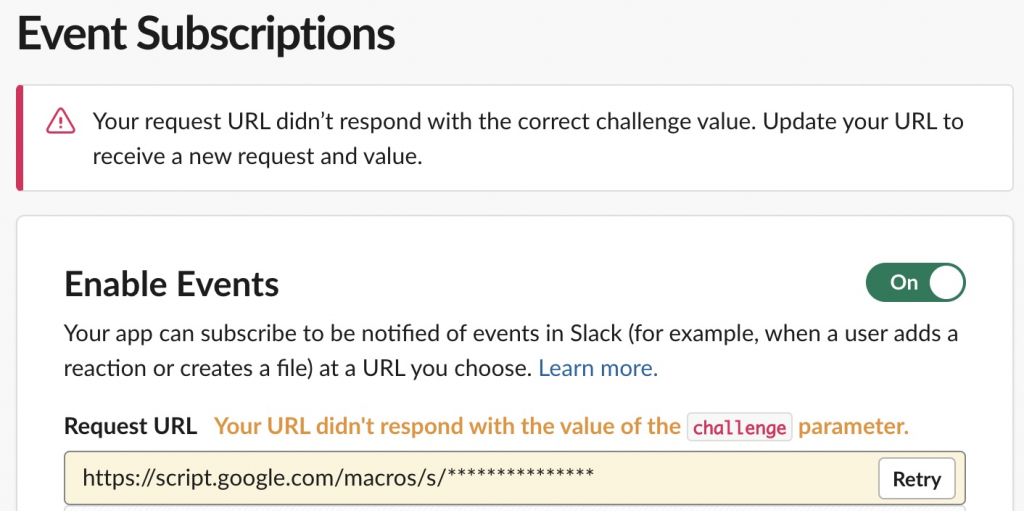
Algo-AI Infrastructure Engineer but also writes programs.The next generation is AI2026-01-08T06:39:58Zhttps://algo-ai.work/en-US/feed/atom/WordPresshttps://algo-ai.work/wp-content/uploads/2020/04/cropped-IMG_7lvr2c-e1586613361896-32x32.jpgalgo-ai<![CDATA[SSL with free SSL certificate from AWS and acceleration with CDN]]>https://algo-ai.work/?p=21492026-01-08T06:35:06Z2025-08-28T05:17:00ZWe will show you how to SSL-ize your website using your Name.com domain and a free certificate from AWS. The method we will show you uses Name.com instead of AWS’s Route53. If you have a multi-year contract for a domain, only the domain may not use AWS. You can continue to use Name.com without migration and use AWS Cloud Front and Certificate Manager to SSL-ize your website.
Free AWS Certificates
AWS can issue SSL certificates for free at the AWS Certificate Authority. They are also automatically renewed. On regular Linux servers, you can use Let’s Encrypt for free SSL certificates. If you are interested, please also read the following article.
AWS provides free certificates through AWS Certificate Manager (ACM).
AWS Certificate Manager is a service that makes it easy to obtain, manage, and use trusted SSL/TLS certificates on the Internet; ACM allows you to obtain various types of certificates, from creating self-signed certificates to signing certificates from public CAs.
In particular, AWS offers free certificates through Public Certificates in AWS Certificate Manager (ACM). Public Certificates automatically issues and manages Domain Validation (DV) SSL/TLS certificates, which are signed by an official CA to prove ownership of the domain.
SSL Certificate Creation
Access Certificate Manager.
Send a request to obtain an AWS signed certificate. The certificate will not be issued until the validity of the domain is proven.
Request a public certificate. The fully qualified domain name is the domain you plan to use. In this case, it is the domain used by Name.com. Leave the other defaults as they are and click Request.
If you look at the status of the certificate after the request, you will see that the status is pending and the CNAME name and CNAME value are listed. To prove that you have the domain, register this information as a cname record at name.com to prove that you own the domain. When the proof is complete, the message “Success” will be displayed.
Setting up cname in your dns
Set cname in dns to prove that you own the domain in AWS.
Configure CNAME settings in DNS.
Here is an example of using お名前.com.
A CNAME record is a mechanism that allows you to tie a formal name to an alias. It is interesting that you use this mechanism to indicate that you hold a certificate.
Go to お名前.com and from the Domains tab, click on “Domain DNS Settings”.
Click the “Configure” button under Use DNS record settings.
Add a CNAME record: select “CNAME” for TYPE, enter “CNAME Name” for the hostname, and enter “CNAME Value” for the VALUE. Click the ADD button to confirm and configure.
After registration is complete and a short while later, the AWS side request is completed and the certificate is issued.
Select a certificate in Cloud Front and publish it on the web
Set the created certificate to Cloud Front. Create a distribution and select the origin domain where the published web server information is located.
Set an alternate domain name (CNAME) to use your お名前.com domain. Use the same name as the certificate.
Select an SSL certificate. You can use a certificate that has been requested and created.
Cloud Front should be able to publish the web server. If you can wait a few minutes, copy the distribution domain name and access it with the URL in another tab of your browser, you have succeeded.
Conclusion
We have shown you how to convert your website to SSL using a DNS Service domain and an SSL certificate. The certificate is free of charge and can be renewed automatically. In addition, by using Cloud Front, we were able to improve security with AWS Shield and speed up the process with CDN.
]]>0algo-ai<![CDATA[Ansible Using the ansible command in AWS]]>https://algo-ai.work/?p=27592026-01-08T06:36:33Z2025-08-28T04:28:00ZWe will build a virtual runtime environment on AWS and use ansible commands We will try ansible using only commands, not a playbook We will prepare a RHEL7.7 server on AWS EC2 and build a virtual runtime environment for python We will install ansible and run ansible commands using the module on localhost. Install ansible and run the ansible command using the module on localhost.
Set up t2.micro on AWS EC2
Try ansible on AWS. We selected and created an AMI of Cent OS7.
cat /etc/redhat-release
Red Hat Enterprise Linux Server release 7.7 (Maipo)
Create an Ansible user and allow SSH connection
sudo su
useradd -s /bin/bash -m ansible
passwd ansible
echo "ansible ALL=(ALL) NOPASSWD:ALL" |tee -a /etc/sudoers.d/ansible
sudo su ansible
Install ansible in a virtual execution environment (virtualenv)
When reconnecting to the virtual execution environment, do not forget to do the following again.
su - ansible
cd
source ./venv/bin/activate
If you try typing the command and the help contents are displayed, the environment has been successfully built.
ansible-playbook --help
ansible --help
Try Ansible commands
Try the ansible command. As a simple command, run the setup module against localhost. setup is a module to get information about the device. The command is to get information about yourself. You can retrieve a lot of information.
ansible localhost -m setup
If it does not work, you may not be able to connect to localhost with ssh. You must be able to connect to localhost with ssh.
ssh localhost
To type a shell command in ansible, use the command module. You can use the shell command with any command, and you can see that there is a venv directory.
There are various modules besides the setup and command modules. By understanding the modules, you will know what you can do with ansible. It is a good idea to search the official documentation page you are interested in. All modules are listed on the page, and you can use your browser’s search function to find out more.
As an introduction, here are some commonly used modules.
<yum module>
yum can specify present(install), etc. with the state parameter. The state can be abcent,installed,latest,present,removed. If you set “present”, you can install. I run python install and changed is false because it has already been installed.
The command specifies the inventory file with the -i option. The same can be done with the -i option.
ansible -i inventory.ini web_servers -m setup
non-flammable module
The following commands are not guaranteed to be valid. If you use them, you must include a conditional branch and make sure that they work properly. Viability is the property that an operation will produce the same result even if it is performed multiple times. This is one of the strengths of Ansible, and it is necessary to create a playbook so as not to lose it. To keep it simple, we should use the modules that are already in place and be careful how we use them.
command
expect
psexec
raw
script
shell
telnet
Conclusion
I have built an ansible environment on AWS and tested simple ansible commands. I would like to learn how to automate without losing the functionality of ansible, and I would also like to learn the quirks of ansible.
]]>0algo-ai<![CDATA[Multi-stage Proxy server on AWS EC2 with Squid]]>https://algo-ai.work/?p=27162026-01-08T06:39:01Z2025-08-23T05:26:00ZSaaS is all the rage, and sometimes you want to use SaaS proxies from your internal network. We will show you how to set up a quick proxy server in AWS and implement a multi-stage proxy configuration.
Set up EC2 in AWS
First, prepare a server on AWS to set up a proxy server. You can quickly create it on AWS. If you get used to it, you can build an EC2 server in less than 30 minutes, but it can be a little tricky at first, so I will briefly describe some key points. Before building the server, you will need to create an Internet gateway and routing table in advance to assign a virtual private cloud and global IP. It is like creating a zone or configuring a router.
Point 1: Build a VPC (Virtual Private Cloud).
Point 2: Create an Internet gateway.
Point 3: Build a route table.
Point 4: Run Cent OS on an EC2 instance. The t2.micro within the free framework is enough to try it out. Don’t forget to enable automatic assignment of public IPs in the network settings. Security groups allow ssh traffic.
From your terminal, specify the ssh.key with the -i option and connect using ssh. If you can connect, it is OK. I tried it with my smartphone and was able to access the site in less than 30 minutes.
ssh -i xxx.pem ec2-user@x.x.x.x
Build a Squid server and put in the settings for multistage proxying.
Install squid on Cent OS.
# yum -y install squid
Change the configuration of squid to a multi-level proxy setting.
Add a never_direct setting to the “/etc/squid/squid.conf” configuration to prevent direct access. In addition, add a FQDN setting in cache_peer to indicate the parent proxy server. The [FQDN] portion should be the domain name of the SaaS server that provides the proxy service.
If you do not include never_direct, the server may be accessed directly without going through the parent proxy server, so be sure to include the never_direct setting as well.
never_direct allow all
cache_peer [FQDN] parent 8080 0 no-query
On the other hand, if you put always_direct allow all, the web server will always be accessed directly, without going through the parent proxy server, and you can use different ACLs to set up some communications without multistage proxying and some communications with multistage proxying. The ACLs can be used in different ways.
Conclusion
This is a brief description of how to build EC2 on AWS and implement a multistage proxy configuration, including a SaaS proxy, with Squid. If you want to use a multistage proxy configuration using SaaS, please give it a try.
]]>0algo-ai<![CDATA[Migrate your own VMDK by uploading a snapshot in the AWS Console]]>https://algo-ai.work/?p=26612026-01-08T06:39:58Z2025-08-23T04:47:00ZWhen EC2 image-import does not work, import-snapshot can be used to import on AWS. We will show you how to migrate an existing virtual server (vmdk) via snapshot. vmdk files that cause errors when creating an AMI can be created based on a snapshot as a way to force an AMI. You can avoid the error process and set up an EC2 server based on a local vmdk file.
Upload vmdk file to S3
Upload the vmdk to the AWS storage service S3. We assume that you already have the vmdk on hand; on ESXi, you can get the vmdk file by right-clicking on the target virtual server and exporting it. You can upload the file to S3 by drag and drop on the web screen, which is a GUI operation. Click Upload, select the file and press the Upload button to upload it.
Note the S3 URI, such as “s3://backet/test.vmdk”. This is so that the command can specify the S3 URI to move to the snapshot.
M1 mac to be able to use aws console
On a Mac, enter the following into the terminal and install it so that you can use aws console.
brew install awscli
aws configure
Set the AWS Access Key ID and AWS Secret Access Key or Default region name. To obtain an Access Key ID and Secret Access Key, go to the AWS web page, select a user on the IAM screen, go to the Authentication Information tab, and click Create Access Key.
Configure IAM as vmimport role
Create a role that can import vmdk into AWS. Create a trust-policy.json file and create the policy with the aws conwole command.
Create a trust-policy.json file with the vi command.
Create an image from a snapshot and create your own AMI
If it can be imported into AWS as a snapshot, the rest can be handled by manipulating it in the GUI environment.
Open the Elastic Block Store snapshot and you will find the snapshot you registered. Select it and check it.
Select [Create Image from Snapshot].
Create an image by selecting an image name and architecture. In this case, we created an image named test.
You have now created your own AMI. EC2 will start up as usual, so you can set up your server as you like by selecting the AMI image you created from “My AMI” and choosing the instance type, etc.
Conclusion
In this article, we have shown how to convert your own VMDK file to a snapshot, create your own AMI image, and build an EC2 server. Now you can try to migrate your vmdk file onto AWS. If you are having trouble with errors using other methods, please try creating your own AMI image from a snapshot.
]]>0algo-ai<![CDATA[Using unsupported plugins without upgrading WordPress]]>https://algo-ai.work/?p=28582023-02-03T08:47:18Z2023-02-03T08:46:33ZMany WordPress users may not want to upgrade. On the other hand, you would like to install new plug-ins. In such cases, we will show you how to install a plugin that is not yet compatible with the current WordPress version without upgrading WordPress.
Plugins that are not yet supported by the current WordPress version
In my own case, when I tried to download Bogo, I was prompted to update WordPress. It is incompatible with the WP version in use, and I would consider updating WordPress first. On the other hand, if you do not want to update WordPress, you may give up on installing this plugin because the version is incompatible. You don’t have to give up, you can install one that is compatible with your current WordPress.
Download older versions of plug-ins
Download the older version of the plugin and download the one that matches the current WordPress version. Here is how to transition to get to the older version of the plugin.
Click on “WordPress.org Plugins Page”.
Click on the “Development” tab.
Click on “Show Details.”
You can specify the development version and download it. You can download multiple versions of the plugin and install them to test if they are supported.
Install older versions of plug-ins
From Add New Plug-in, click “Upload Plug-in” to upload and activate the downloaded plug-ins and find the available plug-ins.
If we could eventually find a working version of the plugin, we could use it by matching the plugin version to the WordPress version.
security
It is important to keep in mind that because you are dropping the plugin version, you are using a degraded version of the plugin rather than the latest one for security purposes. A countermeasure to avoid this situation is to enhance security by publishing a static version of the WordPress site instead of publishing the dynamic WordPress site itself.
We showed you how to install a plugin that is not compatible with the current WordPress version without upgrading WordPress. You can use the plug-ins you want to use. In addition, we have also published a separate article on how to avoid the disadvantage of reduced security by only publishing static pages instead of dynamic WordPress pages, in case of reduced security due to plugin version down.
]]>0algo-ai<![CDATA[Try Ansible’s conditional branching.]]>https://algo-ai.work/?p=28222023-02-02T13:41:44Z2023-02-02T13:38:38ZAnsible’s strength is its simplicity, and it is not good at verification and complex processing. Conditional branching is a process that can become complicated and should not be actively incorporated, but there are times when you really want to do conditional branching. Let’s try conditional branching.
Stores the result in a variable and executes it when it matches when.
Conditional branches can be specified with when. The following is an example of executing cat /etc/redhat-release when ansible_os_family is RedHat.
---
- name: Test Playbook
hosts: test_servers
tasks:
- name: Check OS Family
debug:
var: ansible_os_family
- name: Check OS Version
command: cat /etc/redhat-release
when: ansible_os_family == "RedHat"
Conclusion
I tried Ansible’s conditional branching, which is simple, but allows you to conditional branch on when and have the command executed.
]]>0algo-ai<![CDATA[Create a Language Change item in Menu.]]>https://algo-ai.work/?p=27852023-01-28T05:24:54Z2023-01-28T05:24:32ZI would like to show you how to create a Language item in the Menu to make your site multilingual. What I will show you is how to create a Language item with the same level of notation as the categories and allow you to select English or Japanese.
What we want to do
The idea is to be able to choose Japanese, English or other language conversion when selecting a WordPress menu item to set the language. What we want to do is simple, but not a standard feature of Bogo.
Configure settings from Menu
Select Menu from Appearance.
Select the menu and you will see that you can add fixed pages and custom links. In the custom links, create a Language, and Japanese and English with Language as the parent.
When you create the menu, you can create the menu structure. Under Language, put the URL for the Japanese top page in Japanese and the URL for the English top page in English. This will create a Language item in the menu and allow you to select Japanese/English.
Conclusion
We introduced the method of creating a Language item in Menu to achieve a multilingual site. We decided to take this approach because we thought it was redundant information to allow language settings using a person frame on the page.
]]>0algo-ai<![CDATA[Omit index.html in Cloud Front]]>https://algo-ai.work/?p=27292023-01-23T05:35:29Z2023-01-23T05:33:59ZHow to access index.html in subdirectories with Cloud Front by omitting the file name I was stuck when I published S3 with wordpress static files on the web and it didn’t see the index.html in the subdirectory Cloud Front + S3 with CDN and SSL support for web publishing is appealing. If you can publish a site that doesn’t fall down smoothly, that would be the only way to get the job done.
What we want to do
When I wanted to see the “https://learning-english.algo-ai.work/category/grammar/index.html” file, I wanted to see the “https://learning-english.algo-ai.work/category/ I wanted “grammar/” to automatically look at the index.html file. since WordPress places Index.html in each permalink directory by default, I didn’t want to do it by stating index.html after I made it static, so I looked for a way I searched for a way to do this.
Redirect by function
CloudFront allows you to select a function in addition to a distribution. We decided to write a program that will automatically write index.html at will by selecting a function from the tab.
Proceed with the creation of the function and include the following code in the development tab
function handler(event) {
var request = event.request
var uri = request.uri;
if (uri.endsWith('/')) {
request.uri += 'index.html';
} else if (!uri.includes('.')) {
request.uri += '/index.html';
}
return request;
}
Click on Publish Function and Add Associations and select the distribution to which you wish to automatically grant index.html.
This is the end of the configuration, so when you access the “Distribution Domain Name”, you will automatically be able to access the site that requires index.html.
Conclusion
We have introduced some of the problems we encountered when publishing a web server with Cloud Front, and how to make WordPress static and publish websites with Cloud Front + S3 for blazing speed. Please read it as well if you like.
]]>0algo-ai<![CDATA[Using the Convert for Media plug-in in NGINX]]>https://algo-ai.work/?p=27032023-01-23T05:20:01Z2023-01-23T05:18:34ZThe next generation of image file formats, such as WebP and AVIF, are being developed in secret, and when converting to WebP or AVIF in WordPress, NGINX requires additional settings. In this case, we will use Convert for Media. When I used other plug-ins, there was a limit to the number of images that could be converted, which led me to Convert for Media.
Why should you WebP?
This is because next-generation image formats are very lightweight and faster to access. A file of several hundred KB will turn into a file of several dozen KB, and the response time will be faster. Because of the expected increase in storage capacity efficiency and faster access speeds, I actively use next-generation image formats.
Add Convert for Media
Search for and install the Convert for Media plugin from WordPress, and activate the plugin.
Once activated, the Convert for Media field will be added to the media tag, which can be set by clicking here.
NGINX Settings
NGINX requires additional configuration. Configure the following settings in your NGINX configuration file, such as /etc/nginx/conf.d/default.conf.
# BEGIN Converter for Media
set $ext_avif ".avif";
if ($http_accept !~* "image/avif") {
set $ext_avif "";
}
set $ext_webp ".webp";
if ($http_accept !~* "image/webp") {
set $ext_webp "";
}
location ~ /wp-content/(?<path>.+).(?<ext>jpe?g|png|gif|webp)$ {
add_header Vary Accept;
expires 365d;
try_files
/wp-content/uploads-webpc/$path.$ext$ext_avif
/wp-content/uploads-webpc/$path.$ext$ext_webp
$uri =404;
}
# END Converter for Media
Restart NGINX, activate the settings, and you are done.
systemctl restart nginx
Run Convert for Media
Check the default settings.
WebP is checked.
Make sure uploads is selected. This is the folder where the images are uploaded.
Click on Start Bulk Optimization to run it, and the conversion to WebP images will run. There is no limit on the number of images.
If you fail…
The default settings do not delete the original file; you can restore it by deleting the settings in NGINX and restarting. If you make a mistake, do not be in a hurry to correct it.
Perhaps the NGINX path is different, so if you rewrite it to the correct path and run it, it will work.
Conclusion
We have shown you how to convert to WebP using Convert for Media in NGINX. Please try this method as it is expected to reduce the image size and speed up the response time.
]]>0algo-ai<![CDATA[Staticize wordpress with staatic and publish on the web with s3]]>https://algo-ai.work/?p=26902023-01-23T05:11:18Z2023-01-23T05:08:26ZHere is how to make wordpress static and do static web hosting on AWS S3. we tried static press, wp2static, and simply static, but it didn’t work, such as changing php timeout time settings, so we used staatic I used staatic to make WordPress static. Once it was static, I was able to publish it on the web using AWS S3 and
Installing staatic
Static is a plugin that turns WordPress into a staticized site. There are multiple candidates for a staticization plugin, but I am confident that this plugin is the only one that has been successfully staticized.
Install Static from “Add Plugin” in WordPress. You can install it by searching and pressing the Install button. Press the Enable button to activate it.
A tab will appear at the bottom of the menu.
We have migrated to a different domain; the URL describes the domain you want to use.
Click on “Publish now” from Publications to make it static.
Unfortunately, however, xfree did not work in a https environment.
Where I got hooked.
In xfree, it did not work well with https, so changing the configuration to http worked.
Disable SSL settings and press Publish Now and it works.
Other important permalink settings
Some permalink settings may not work properly. From the Settings tab, click on Permalinks to set the format of the permalinks that are supported.
Myself, I selected “post name” and it worked. The folder structure is such that index.html is placed in a folder with the name of the article, such as /sample-post/.
In addition, when going to SSL, I was stuck with the fact that it would not access index.html for each folder; Cloud Front uses Function to redirect it, and it works. I will show you how to do this in another article.
Conclusion
I have shown you how to staticize your WordPress pages with Static, I thought it would be cosmetic to publish them with S3 + Cloud Front, so I am staticizing them and publishing them on the web. I like the fact that it eliminates the need for specs on the web server where I write the articles.
]]>0algo-ai<![CDATA[Ansible Advantages and Disadvantages]]>https://algo-ai.work/?p=26752023-02-02T13:54:03Z2023-01-23T04:51:21Z
Ansible is an open source orchestration and configuration tool. By writing simple YML files, you can automate a variety of infrastructure, including networks, servers, and clouds. In this article, we will learn the basics of YML files and how to automate your infrastructure infrastructure frame using Ansible We considered the advantages and disadvantages of Ansible.
Should be automated by promoting cloud computing
First, cloud computing is being used, but cloud computing is pay-as-you-go. The cost is high, so an operation that provides infrastructure when needed and removes the environment when it is not needed is suitable. The cloud is expensive and can be used when the case is right. In many cases, I want to use the verification environment temporarily, so it is beneficial to be able to create the verification environment quickly and only when I want to use it if I can build it automatically. Let’s use Ansible to automate and make the most of the cloud. On the other hand, there is also the generous Oracle Cloud Infrastructure that offers servers that can be used for free for many years. If you are interested, please read this article as well.
Infrastructure as Code is the automation of infrastructure construction and modification tasks that used to be done manually, but are now defined in code. What has been done in the application can be applied at the infrastructure layer to manipulate infrastructure resources with code. Managing the infrastructure with code would have the advantage of reducing operating costs, improving quality, and making governance more effective by standardizing the work. On the other hand, while design documents and the like may no longer be needed, the code itself must be managed by version control and CI tools. It will take time for infrastructure engineers to understand how to operate more than applications.
Scope of Infrastructure as Code
There are three areas that can be automated with Infrastructure as Code: Orchestration, Configuration Managemetn , and BootStrapping. Simply put, the three layers are Application, OS, and BIOS. Tools that can automate at each layer include Capistrano/Fabric, CFEngine/Puppet/Chef, AWS/VMware/Docker, etc. It can get complicated if multiple tools have different defenses, so it is better to have a tool that can cover them all. So, one tool that can do multi-layered orchestration is Ansible, which covers the scope of all three. Ansible can be used without an Agent on the client side as well, so as long as you have an ssh connection, you can proceed with the automation. In this article, we will introduce Ansible.
What is Ansible?
Ansible is an open source orchestration and configuration tool developed for infrastructure automation. Ansible is an open source orchestration and configuration tool developed for infrastructure automation. YML files are sets of instructions for automating the infrastructure.
YML Basics
YML (YAML Markup Language) is a concise markup language for automating infrastructure configuration. we often create Ansible playbooks by following three rules for writing YML files
Use two spaces to create indentation.
Use a colon (:) to associate a keyword with a value.
Use a hyphen (-) to indent list items.
The simplicity of the YAML format makes it easy to read and write, and it is characterized by low learning costs and low genus.
A specific example is shown below, starting with “—“.
YAML is simple, so using Ansible offers the benefits of simplicity. On the other hand, complex processing including conditional branching requires ingenuity, and overcomplicating the process will weaken the benefits. It is important to reduce the process to a simple operation and automate it.
Advantages and disadvantages include
.
easy configuration management; Ansible requires no programming skills and uses the YAML language to define host and service configurations using Playbooks.
multi-platform support; Ansible supports many operating systems (Linux, UNIX, Windows) and services (MySQL, Apache, nginx). You can grasp the details by checking the module index.
lightweight and scalable. It is lightweight and scalable; the architecture that Ansible incorporates does not require you to manage all of your servers and is fast.
With Ansible, your infrastructure configuration becomes code in the form of code files. This makes it easy to track how applications and servers are configured. It also allows you to unify server configurations and simplify changes.
<Disadvantages.
Ansible is not suited for building customized and flexible infrastructure. You should set up a simple configuration.
it is not suited for complex operations, and Ansible’s looping syntax seems to be very cumbersome.
when using Ansible with virtual machines, you need to define the environment of the virtual machine with variables.
Ansible defines and automates Inventory and Playbook
As a simple configuration, you define Inventory and describe what to do in Playboook to move it along. If we consider that we only define what to do and how to do it, it is a good idea to have a simple concept. As an Inventory, we describe parameters such as IP address, etc. We define it as inventory.ini. It can be grouped into any group name, such as [web_servers], [db_servers], etc. The all group is defined implicitly and refers to everything listed in the inventory file.
As a playbook, define what to do for the above inventory: define site.yml. The example below shows how to yum start httpd on 192.168.10.1/192.168.1.2 defined in yml.
It is a simple image that configures what to do and for what. Execution can be done by specifying inventory and yml.
ansible-playbook -i invent.ini site.yml
What happens when you execute the same thing twice?
Ansible guarantees completeness, which means that multiple runs can be made without error and the program will move on to the next task. Therefore, there is no need to describe conditional branches for error handling, which simplifies the playbook. However, if you use a highly flexible module such as the command module, you will not be able to use one of the advantages of ansible. It is better to use the command module as a last resort.
Conclusion
As an introduction to Ansible, we have introduced the advantages and disadvantages of Ansible. Ansible is simple and can be used for a wide range of applications. The community version is free to use, and I would like to try both the CLI/GUI versions.
]]>0algo-ai<![CDATA[SSL with Let’s Encrypt on AWS Cloud Front]]>https://algo-ai.work/?p=26452023-01-23T04:33:22Z2023-01-23T04:33:20ZGo SSL with AWS Cloud Front using a Let’s Encrypt certificate. You can start publishing SSL-enabled web pages for free with unbeatable pay-as-you-go pricing. Cloud Front charges based on the number of hits, and if you can get an SSL certificate for free, you can get started for free. Learn how to provide an explosive and secure site with Cloud Front.
M1 Get a Let’s Encrypt certificate on your Mac
Get a free certificate at Let’s Encrypt. M1 We will show you how to obtain a certificate on a Mac environment, assuming that you are able to publish your webbase on S3. The following article will show you how to do this.
After installation, it is installed in [/opt/homebrew/Cellar/certbot/2.1.0/bin/certbot]. In my environment, the link was not put in bin. I tried to use it as it is without linking.
command seems to work. Let’s create the certificate as is without the symbolic link. If you want to issue a certificate for learning-english.algo-ai.work, the command will look like this
When you type, the message “Create a file containing just this data” is displayed, so create a file in S3 for authentication, place it there, and authenticate it.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Create a file containing just this data:
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
And make it available on your web server at this URL:
http://learning-english.com/.well-known/acme-challenge/xxxxxxxxxxxxxxxxxxxxxxxxxxxx
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Press Enter to Continue
Upload the entire .well-known to S3 and press [Enter] to approve and issue the certificate.
The set of certificates will be located in “/etc/letsencrypt/live/learning-english.algo-ai.work/”.
Send a set of certificates to Cloud Front
Send a set of certificates to Cloud Front via AWS command.
Create IAM user
First, create a policy to grant privileges to the IAM user: create the following in the JSON tab, return to the visual editor, continue to the next step and press the “Create Policy” button. If you do not see the button on the screen, you can see it by reducing the text on the web screen.
After creating the policy, open IAM and create a user.
Add a user.
Create a user with certificate privileges in the policy you created.
Select the user you created and choose the Authentication Information tab.
In the “Access Key” field, you will create an access key.
You will get an access key and secret access, which you should write down and use later in aws console.
Send certificate to Cloud Front with aws cli
Install the awscli command on m1 mac.
brew install awscli
Type “aws configure” and you will be asked for the Access Key ID and Secret Access Key.
aws configure
AWS Access Key ID [****************]:
AWS Secret Access Key [****************]:
Default region name [ap-northeast-1]:
Default output format [json]:
Upload the certificate using the aws command. Change the directory name to your domain name and execute.
Set the created certificate to Cloud Front.
Create a distribution and select the origin domain where the published web server information is located.
Set an alternate domain name (CNAME) to use your own domain.
Select the SSL certificate. If you have the certificate you just uploaded, you have succeeded.
Cloud Front should be able to publish the web server. If you can wait a few minutes, copy the distribution domain name and access it with the URL in another tab of your browser, you have succeeded.
Connect your own domain to CloudFront with Name.com
Set up a cname at Name.com so that you can access the S3 URL from your own domain.
Configure CNAME settings in DNS.
CNAME records are a mechanism that allows you to associate an alias with a canonical name, so that you can access AWS with your FQDN, and then associate it with your canonical name to access your own domain.
Go to Name.com and from the Domains tab, click on “Domain DNS Settings”.
Click the “Configure” button under Use DNS record settings.
Add a record, selecting “CNAME” for TYPE, with any subdomain name for the hostname and the AWS CloudFront URL for the VALUE. Click the ADD button to confirm and configure.
Conclusion
We have shown you how to use Let’s Encrypt certificates to SSL-ize your website on AWS Cloud Front. Now you can build a CDN environment with enhanced security, and create a blazing-fast website.
]]>0algo-ai<![CDATA[Improved chat GPT with multilingual support and chat accuracy]]>https://algo-ai.work/?p=25982023-01-21T07:46:44Z2023-01-21T07:46:01ZChat GPT no longer supports Japanese, so we will show you how to use it with multilingual support. We will show you how to use OpenAI’s API in two steps, and how to use Google Apps Script to improve the accuracy of the response through translation by Google API. Chat GPT is an AI built mainly on English data. As a matter of course, if you use it in a language other than English, its accuracy will be inferior to that of English.
How to use chat GPT in Line
Using OpenAI’s API, you can use Google Apps Script to support LINE to use AI that supports Japanese. You can try it out for free, and you can use it conveniently by paying out your LINE business account, writing a simple script in Google Apps Script, and linking it together to support it. Please try the following article for more details. In addition, please read “Translating with Google Apps Script” on this page, and you can try the highly accurate chat function by using the additional translation API.
https://algo-ai.work/2022/12/19/post-1561/
How to use chat GPT in Slack
Using OpenAI’s API, Google Apps Script can be used to support Slack so that it can be easily touched by the team and also in Japanese. If you can integrate it into Slack, it would be convenient for your team to touch it easily. Please check the following article for more details. In addition, please read Translating with Google Apps Script on this page to try out the highly accurate chat functionality by using the additional translation API.
https://algo-ai.work/2022/12/24/post-1607/
Translate with Google Apps Script
getChatGptMessage is functionalized in the script created in the previous section. Google Translate is interspersed with LanguageApp.translate. Translate Japanese into English and use openAI’s API in getChatGptMessage. Store the response in content, translate it and store it in content. Now you can use chat GPT with high accuracy by using the API in English and also in multiple languages.
var temp;
temp = LanguageApp.translate(message,"ja","en"); //English
var content = getChatGptMessage(temp);
content = LanguageApp.translate(content,"en","ja"); //Japanese
Conclusion
We have shown you how to use chat GPT in a highly accurate way in Japanese. To ask questions in English, you can use the translation API for better accuracy, so please try it out if you use chat GPT on a regular basis.
]]>0algo-ai<![CDATA[Comfortable using Chat GPT]]>https://algo-ai.work/?p=25762023-01-21T07:35:23Z2023-01-21T07:32:42ZUsing the web version of chat GPT can cause network errors and slowness. Here is a way to get answers in batches. I tried this because it was depressing to see the text appear little by little.
Make it compatible with Line
Using OpenAI’s API, you can use Google Apps Script to support LINE to receive answers to replies easily and in bulk. It is possible to put this into practice free of charge. If you can use it on LINE, you can easily use it as if you were Googling. Please check the following article for more details.
Using OpenAI’s API, you can use Google Apps Script to support Slack, making it easy for your team to touch and receive responses to replies in bulk. This is a free practice. If you can integrate it into Slack, it would be convenient for your team to touch it easily. Please check out the following article for more details.
We are pleased to present an article on easy access to chat GPTs. If you can touch the latest AI chatbot embedded in LINE or Slack, you can make some progress. Please give it a try.
]]>0algo-ai<![CDATA[Enabling Chat GPT on LINE]]>https://algo-ai.work/?p=25632023-01-21T07:20:45Z2023-01-21T07:20:15ZChat GPT is being talked about as a chat bot that is too smart. We will show you how to implement it on LINE so that you can easily touch it.
If you can consult with us on LINE, you can consult with the chat bot about anything at any time. I myself have implemented it on LINE and use it casually as if I were Googling.
When I tried to get an access token for LINE after a long time, the page transition had changed, so I will also show you how to get an access token on the latest LINE page.
How to obtain an access token and secret token for LINE Bussiness
Register and login to LIne Bussiness.
Click Create to create a new BOT. Agree to create an account and create a provider.
Click on the Chat tab, then click on “Open Messaging API Settings Window.
The Webhook URL will contain the URL of the server that you later scripted and Deployed in GAS. When this LINE account receives a message, it can send the message received to this server URL to the doPost function.
Click on the Line Developpers link.
Click on the console, select the provider you created, and click on the Messaging API Settings tab.
Issue a channel access token. This access token will be used in the script, so keep it in mind. This will be used when replying (replying to a message) to LINE from the server side. Also, in the response settings, turn off chat and turn on Webhook.
How to obtain an API key for OpenAI
Obtain an OpenAI API key and prepare to create a server-side script.
Sign up below to login, you can also register with a Google Account.
Log in and click Create New Seacret Key to obtain a key for the API. You are now ready to create your script.
Google Apps Script (GAS) Script
Prepare a server in a serverless environment with Google Apps Script. Create a project and script at the following URL
In the script, enter the string that you have just memorized in the [your OpenAI API key] and [your Line channel access token] fields.
// Call ChatGPT's API and return response
function getChatGptMessage(message) {
var uri = 'https://api.openai.com/v1/completions';
var headers = {
'Authorization': 'Bearer [API key of own OpenAI]',
'Content-type': 'application/json'
};
var options = {
'muteHttpExceptions' : true,
'headers': headers,
'method': 'POST',
'payload': JSON.stringify({
"model": "text-davinci-003",
"max_tokens" : 2048,
"prompt": message})
};
try {
const response = UrlFetchApp.fetch(uri, options);
var json=JSON.parse(response.getContentText());
return json["choices"][0]["text"];
} catch(e) {
console.log('error');
}
}
//Get e object when message is received
function doPost(e) {
let token = "[Own Line channel access token]";
// Obtained as JSON data
let eventData = JSON.parse(e.postData.contents).events[0];
// Obtain tokens for reply from JSON data
let replyToken = eventData.replyToken;
// Get message from JSON data
let userMessage = eventData.message.text;
// Define API URL for response messages
let url = 'https://api.line.me/v2/bot/message/reply';
// Prepare reply message from JSON message
let replyMessage = userMessage;
//Set payload value with text for messages returned by the defined chat GPT
let payload = {
'replyToken': replyToken,
'messages': [{
'type': 'text',
'text': getChatGptMessage(replyMessage)
}]
};
//Set POST parameter for HTTPS
let options = {
'payload' : JSON.stringify(payload),
'myamethod' : 'POST',
'headers' : {"Authorization" : "Bearer " + token},
'contentType' : 'application/json'
};
//Request and reply to LINE Messaging API
UrlFetchApp.fetch(url, options);
}
Once you have created the script, click New Deploy, click the gear and select Web app. in Who has, select anyone and click Deploy. log in with Authorized access and approve.
Click Deploy to create a web URL and copy it.
Paste it into the LINE Webhook URL, save it, and you are done.
You can now freely use the chat GPT, on line.
Conclusion
We have shown you how to easily touch the chat GPT on line. Now you can consult chatBot anytime. If you have the ability to use AI on your smartphone, you can write enough code. It is also great that you can easily use it as if you were Googling.
]]>0algo-ai<![CDATA[Automation of testing using multiple devices with shell scripts]]>https://algo-ai.work/?p=25472023-01-21T07:06:17Z2023-01-21T07:00:43Z
We believe that everyone is implementing test automation. If you want to automate a combined or comprehensive test that straddles multiple devices rather than a single device, you can do so flexibly with shell scripts, which we will introduce here.
Login with Script
Create a shell script to login to the terminal to be connected via ssh. For the public cloud, the key is specified with ‘-i’ to log in using a key. Also, it is common to leave fingerprints when logging in, but an error occurs when logging in with VIP, so the ‘StrictHostKeyChecking no’ option is specified to ignore fingerprints. In addition, the ‘-t’ option allows the command to be executed as a pseudo-terminal.
You can log in by actually running the script you created to see if it is usable.
% sh login.sh
Create the script you want to run
Create a script that you want to run.
Here we simply obtain the date and time.
◆work.sh
#!/bin/bash
date >> test_work.txt
date
exit
Execute shell script
Prepare a work.sh script that describes what you want to execute. Pass this script file at login. After multiple shell executions, download the file that outputs the execution results and receive the results.
When executed, the file can be retrieved automatically.
sh auto.sh
You can also run multiple shells simultaneously. By running them in the background (&) and waiting for the process to finish, you can make simultaneous connections via ssh.
Here is an example of how to apply this to access and log the web while retrieving log files. The following script will retrieve a new Nginx access log for 10 seconds.
While accessing with work2.sh, you can automate the sequence of accessing from your own terminal with curl and acquiring logs, so that you can perform the test.
If the end result is to compare the results with the expected values, I believe the test can be automated by compiling the downloaded log files into Excel and comparing them in Excel.
]]>0algo-ai<![CDATA[Split Google Colab window]]>https://algo-ai.work/?p=25342023-01-21T06:58:57Z2023-01-21T06:58:20Z
How to split a window (split cell display) in Google Colab. You can split and display cells in the same way as you split and develop in Vim on Temirnal. I think you can make good use of it when you describe a long program with cells.
How to split a Google Colab window
Click on the red frame of a cell in the image. The cell will be displayed in a split view when clicked.
If multiple cells are used, only the same cell will be duplicated and displayed.
To display a duplicate of another cell, click the button in the same way in another cell.
Vertically split cell display
You can also change the view to vertical by clicking on the vertical line in the upper right corner.
Cells can be split vertically.
Conclusion
We have introduced a method for splitting a window (how to split a cell into separate displays). I think this can be used effectively when describing cells in a long program.
]]>0algo-ai<![CDATA[403 Forbidden label change in Nginx on Cent OS]]>https://algo-ai.work/?p=25202023-01-21T06:51:01Z2023-01-21T06:47:57ZWhen I create a new file on Nginx on Cent OS, I get “403 Forbidden” and cannot access the file. Solution. I didn’t know that I needed to change the label and got stuck.
Environment
Cent OS 7
Nginx 1.16.1
403 Forbidden
Create a test.html file.
# echo "Hello World" > test.html
403 Forbidden. Depending on your environment, you may not be able to access the file even if you create a new file.
Confirmation of setting status
Check access rights. The following commands can be used to check.
# ls -ltr --context test.html
The options are detailed below. You will also need to check the label.
-l : Show details in long format.
-t : Display files in reverse chronological order.
-r : Reverse the sort order.
–context : Show SELinux security context for each file.
Here is an example of the result. Check other files in the same folder to see the differences.
If “-rwxr-xr-x” is not what you expect, check the other files and change the permissions. You can use the chmod command to change it.
# chmod 755 test.html
Change of Ownership
If “nginx nginx” is not what you expect, check the other files and change the ownership. You can use the chown command to change it.
# chown nginx.nginx test.html
Label Change
If “unconfined_u:object_r:user_tmp_t:s0” is not what you expect, check the other files and change the label. You can use the chcon command to change it.
I think it is easy to miss the point that you need to change the label. If you are having trouble with 403 Forbidden, I suggest you give it a try. If you are interested, please read how to create a GUI environment using the Oracle Cloud’s perpetual free framework.
]]>0algo-ai<![CDATA[Run Windows software on Oracle’s free VPS [Part 2]]]>https://algo-ai.work/?p=24952023-01-21T06:37:13Z2023-01-21T06:29:37Z
I will introduce the second part on how to use EA with a free VPS. In the first part, I posted how to create a VM with OCI and make an SSH connection from your own terminal. In the second part, I will post how to enable a GUI connection to the VPS connected via ssh and start the Windows application MT4 on CentOS.
GUI for Cent OS
Make CentOS GUI. You should be able to make an SSH connection at this point, but you cannot access it via GUI; install GNOME and make it GUI.
Since the Linux Firewall is already configured, it is also necessary to drill a hole in port 3389 on the server side. Since the VCN configuration for the cloud has already been done in the previous section, it is assumed that the drilling of the hole has already been completed.
First, create an account for remote desktop connection via the CLI. Use the following command to create the account and set a password. Be sure to remember the account name and the password you set.
sudo adduser xrdp_user
sudo passwd xrdp_user
After completing the settings on the CUI, you can connect from your own terminal using remote desktop. We recommend using Microsoft Remote Desktop to connect . After installing the application, press the “+” button and “Add PC”. Enter the public IP of the OCI VM in PC Name. Set the set account and password in User Account. In addition, if the purpose is to move MT4 a lot, lower the resolution of the display and reduce the processing of the VM by RDP. On the “Display” tab, select “640 x 480” for Resolution. And if you can save and connect by double-clicking, the GUI login is successful.
Deployment of Wine to run Windows software on Linux
Even if you can log in with the GUI, you cannot start Windows applications as it is, so you will need to install Wine, a software that allows you to run Windows applications on Linux. Since it requires manual make, the process will take some time. log in with GUI, launch Terminal, and input the following reference commands at once and leave it alone. Because of the time required, it is better to enter them all at once and leave it for a day if possible.
sudo yum -y update && sudo yum install samba-winbind-clients -y && sudo yum groupinstall 'Development Tools' -y && sudo yum install glibc-devel.{i686,x86_64} gnutls-devel.{i686,x86_64} freetype-devel.{i686,x86_64} alsa-lib-devel.{i686,x86_64} -y && sudo yum install libtiff-devel.{i686,x86_64} libgcc.{i686,x86_64} libX11-devel.{i686,x86_64} libxml2-devel.{i686,x86_64} -y && sudo yum install libjpeg-turbo-devel.{i686,x86_64} libpng-devel.{i686,x86_64} libXrender-devel.{i686,x86_64} -y && sudo yum install wget && mkdir wine && cd wine && wget https://dl.winehq.org/wine/source/6.x/wine-6.6.tar.xz && tar Jxfv wine-6.6.tar.xz && cd wine-6.6 && mkdir -p wine32 wine64 && cd wine64 && ../configure --enable-win64 && make && cd ../wine32 && ../configure --with-wine64=../wine64 && make && cd ../wine32 make install && cd ../wine64 && make install
Running Windows software. (Running MT4)
Run Windows software with the installed wine. Run automatic trading software mt4 as a software that operates automatic trading for a long time for 24 hours. First, let’s download MT4. XM can be downloaded from here . Gemforex users can download it by clicking the platform and MT4 for PC from here .
After obtaining the exe file, copy and paste the file to the remote desktop and launch the terminal. Move to the directory where the exe file is located, and if you can execute the exe file for setup with the wine command in the installed wine folder, MT4 will start. Then install it in any folder. From the next time onwards, MT4 can be started by starting terminal.exe with the same wine command. Also, when installing multiple MT4s, it is recommended to use separate CentOS workspaces.
We have introduced a free Cent OS VM startup, RDP support, and MT4 boot support. We know it’s a bit challenging, but two VPSs for free in perpetuity is attractive.
]]>0algo-ai<![CDATA[Run Windows software on Oracle’s free VPS [Part 1]]]>https://algo-ai.work/?p=24922023-01-21T06:31:39Z2023-01-21T06:25:57Z
I will show you how to use EA with a free VPS. Normally, just maintaining a VPS will cost several thousand yen per month. In this article, I will introduce how to use Cent OS on Oracle’s cloud and use VPS for free for many years. You can keep MT4 running for free. This article is the first part, and I will post up to the point where you can connect to the newly launched Cent OS with SSH.
Why you need a VPS
The reason you need a VPS to run MT4 is because you need MT4 to work all the time. We know that some of you use your own devices, but keeping your home equipment reliable is not an easy task. In addition, setting up equipment at home involves costs such as securing a place and electricity bills. Therefore, I will introduce how to use VPS using cloud facilities for free.
Free VPS
There are multiple clouds that can be used free of charge forever, but Oracle Cloud Infrastructure (OCI) is recommended for a lifetime free VPS with excellent performance. Because it is popular, depending on the timing, it may not even be possible to launch the VPS due to lack of resources. The long-term free VPS has high performance and can be used for free up to 2VM. In terms of the number of MT4, it is possible to operate dozens of MT4. The second recommended one is AWS, which is free for one year and has lower performance. AWS makes it easy to launch EC2 VMs, and if it’s only for a year, there’s no reason not to use it. AWS was so easy that I could start a VPS in about 30 minutes and connect from my smartphone with remote desktop. On the other hand, the performance was not so good, and the limit was to operate about two MT4s.
Create VM Instance for OCI
Access from here ( OracleCloud ), register and login. Services that can be used free of charge for many years are described as “Always Free Eligible”. Since I want a VPS (Cent OS) that can be operated with a remote desktop, select “Create A VM Instance” to create a VM.
You can select the OS, so select “Edit”, select “Change Image”, and select “CentOS”. (It might be a good idea to use Oracle Linux because it’s a lot of trouble.)
At first, we aim to access with SSH of CLI. Personally, I create an ssh key with security in mind, and copy and paste the contents of “~/.ssh/id_rsa.pub” below. If you are using Mac or Linux, you can use it by typing a command. Since you only need temporary CLI access, you may choose to prioritize convenience by selecting “No SSH keys” here. After gaining access via the GUI, you can limit communication through NW settings and ultimately ensure security.
ssh-keygen -t rsa -b 4096 -C "user@example.com"
Finally, press the “Create” button to create the VM.
NW setting of OCI
First, connect to the created VM using SSH. (It is also possible to use the cloud shell.) The purpose is to access CentOS from the terminal of mac or linux, or Teraterm of windows. This requires drilling holes and setting up a Virtual Cloud Network (VCN). Click the “VirtualCloudNetwork” link from the “Instance Information” tab of the created instance. Since it will be the network settings associated with the instance, follow the links to “Public Subnet” and “Default_Security_List_for_VirtualCloudNetwork_~”. If you trace it, you can register Ingress Rules, so you can set up drilling here.
Press the “Add Ingress Rules” button to set up holes for ssh (port 22). Set SOURCE PORT RANGE to “ALL”, enter “22” to DESTINATION PORT RANGE, and press the “Add Ingress Rules” button. With the above, the ssh hole setting is completed.
Here, it is a good idea to set a hole for port 3389, which is used for remote desktop (RDP), in the same way. Make the same settings by setting SOURCE PORT RANGE to “ALL” and DESTINATION PORT RANGE to “3389” and pressing the “Add Ingress Rules” button.
NW settings are as above. If you want to change the RDP port number to improve security, you need to do the same drilling for the changed port number.
Now that the OCI settings have been completed, let’s access the VM via ssh from your own terminal. The person who created the key must specify the key to connect. Also, the IP accessed via SSH will be the public IP of the instance, so make a note of the IP.
If you want to connect with ssh using the key, the command will be as follows.
ssh -i ~/.ssh/id_rsa -p 22 opc@[Public IP]
Conclusion
In the first part, I posted how to set up Oracle’s free VPS and connect with SSH from your own terminal. In the second part, I will introduce how to connect to Cent OS with remote desktop and run the Windows application MT4. You will be able to keep MT4 running for free.
]]>0algo-ai<![CDATA[[Python] Get millions of data with Oanda FX (78 species/15 years)]]>https://algo-ai.work/?p=24792023-01-21T06:08:36Z2023-01-21T06:08:35ZThis article is for those who want to build big data of time series data . Get 78 types of FX data for 15 years. Machine learning requires a large amount of data. If you want hundreds of thousands to millions of data, this article will be helpful. Use Oanda’s API.
You can see it by pressing the red line on the screen and moving the page.Make a note of the API key obtained here as it will be used.
Whole Code
# coding:utf-8
# Install oandapy
!pip install git+https://github.com/oanda/oandapy.git
# import Library
import time
import oandapy
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
import pytz
# oanda API
api_key = '' # Input API Key
oanda = oandapy.API(environment = "practice", access_token = api_key)
# Function to retrieve 15 years of FX data and output a file (period and interval must be specified)
def get_histry_data(file_path, kind,duration,year_start,year_end,month_start,month_end):
file_name = kind + '_' + duration +'.txt'
ys = year_start
ye = year_start
ms = month_start
me = month_start + 1
res = pd.DataFrame(None)
first_stock = 1
while ye < year_end or (ye == year_end and me <= month_end) :
fmt = '%Y-%m-%dT%H:%M:00.000000Z'
# Convert year and month data to be retrieved into strings that can be used by oandapy's api
start1 = datetime(year=ys, month=ms, day=10,hour=12, minute=5, second=0).strftime(fmt)
end1 = datetime(year=ys, month=ms, day=25,hour=12, minute=0, second=0).strftime(fmt)
start2 = datetime(year=ys, month=ms, day=25,hour=12, minute=5, second=0).strftime(fmt)
end2 = datetime(year=ye, month=me, day=10,hour=12, minute=0, second=0).strftime(fmt)
# Data acquisition using oandapy
res1 = oanda.get_history(instrument = kind,start = start1,end = end1,granularity = duration)
res2 = oanda.get_history(instrument = kind,start = start2,end = end2,granularity = duration)
# Print the time for which data is to be acquired
#print(start1 + " " + end1)
#print(start2 + " " + end2)
# Convert data for one candlestick into a DataFrame
res1 = pd.DataFrame(res1['candles'])
res2 = pd.DataFrame(res2['candles'])
# Data format conversion and change to Japan time
res1['time'] = res1['time'].apply(lambda date: datetime.strptime(date, '%Y-%m-%dT%H:%M:%S.%fZ'))
res2['time'] = res2['time'].apply(lambda date: datetime.strptime(date, '%Y-%m-%dT%H:%M:%S.%fZ'))
res1['time'] = res1['time'].apply(lambda date: pytz.utc.localize(date).astimezone(pytz.timezone("Asia/Tokyo")))
res2['time'] = res2['time'].apply(lambda date: pytz.utc.localize(date).astimezone(pytz.timezone("Asia/Tokyo")))
res1['time'] = res1['time'].apply(lambda date: date.strftime('%Y/%m/%d %H:%M:%S'))
res2['time'] = res2['time'].apply(lambda date: date.strftime('%Y/%m/%d %H:%M:%S'))
# Repeat process for the next month
# When the month is 13, the value is modified to be January of the next year.
ms += 1
me += 1
if ys == 13:
ys = 1
if ye == 13:
ye = 1
if ms == 13:
ms = 1
ys += 1
if me == 13:
me = 1
ye += 1
# Combining two sets of acquired data
res = res.append(res1)
res = res.append(res2)
# Export to file, but add HEADER information only the first time
if first_stock == 1 :
res.to_csv(file_path)
first_stock = 0
else :
res.to_csv(file_path, mode='a', header=None)
res = pd.DataFrame(None)
#main ---------------------------------------------------------------------------------------------------------------
# Where to save files Can also be saved to GoogleDrive
path = './'
# List of Available Currencies
kind = 'USD_JPY'
# List of acquisition intervals
duration = 'M5'
# Print the path of the saved file
file_path = path + kind + '_' + duration +'.txt'
print(file_path)
# get_data(currency_type,time_width,start_year,end_year,start_month,end_month) (get data up to 10 days)
get_histry_data(file_path,kind,duration,2005,2020,1,1)
# Load and print saved data
data = pd.read_csv(file_path)
print(data)
How to use the code
The get_histry_data function can be used to specify the type of currency and the type of time frame.
By changing these parameters and calling the get_histry_data function, 15 years of data can be retrieved. oanda.get_history actually retrieves prices, but only up to 5000 data can be retrieved, so one month of data is retrieved in two batches. Therefore, the program we have created this time retrieves data for one month in two parts. Therefore, the program we have created this time can only retrieve data up to 5 minutes in the shortest interval. In other words, one-minute data cannot be acquired. Also, when using get_history, we have left the code that can output the time used. if you uncomment lines 48 and 49, you can output the period of acquisition, so please try it.
Various data acquisition
The list of currencies that can be obtained with oanda’s API is open to the public. Below is a list of available currencies.
List of Currency Types
The list is below, but please check the oanda HP for details.
Get all information on 78 types of exchange rates in 8 types of timeframes
It may be a little greedy, but it will be the code to get all the data for 15 years. It takes a lot of time to execute, and I think it puts a lot of load on Oanda’s servers. If you run it on GoogleColab, save your data to Google Drive so you only have to run it once.
# path = '/content/drive/My Drive/
# List of Available Currencies
kind = ['USD_JPY','EUR_JPY','AUD_JPY','GBP_JPY','NZD_JPY','CAD_JPY','CHF_JPY','ZAR_JPY',
'EUR_USD','GBP_USD','NZD_USD','AUD_USD','USD_CHF','EUR_CHF','GBP_CHF','EUR_CHF',
'EUR_GBP','AUD_NZD','AUD_CAD','AUD_CHF','CAD_CHF','EUR_AUD','EUR_CAD','EUR_DKK',
'EUR_NOK','EUR_NZD','EUR_SEK','GBP_AUD','GBP_CAD','GBP_NZD','NZD_CAD','NZD_CHF',
'USD_CAD','USD_DKK','USD_NOK','USD_SEK','AUD_HKD','AUD_SGD','CAD_HKD','CAD_SGD',
'CHF_HKD','CHF_ZAR','EUR_CZK','EUR_CZK','EUR_HKD','EUR_HUF','EUR_HUF','EUR_PLN',
'EUR_SGD','EUR_TRY','EUR_ZAR','GBP_HKD','GBP_PLN','GBP_SGD','GBP_ZAR','HKD_JPY',
'NZD_HKD','NZD_SGD','SGD_CHF','SGD_HKD','SGD_JPY','TRY_JPY','USD_CNH','USD_CZK',
'USD_HKD','USD_HUF','USD_INR','USD_MXN','USD_PLN','USD_SAR','USD_SGD','USD_THB',
'USD_TRY','USD_ZAR']
# List of acquisition intervals
duration = ['M','W','D','H2','H1','M30','M10','M5']
# Repeat for each currency list
for k in kind:
# Repeat for each acquisition sense list
for d in duration:
# get_data(Currency type, time range, start year, end year, start month, end month) (Get data up to 10 days))
file_path = path + k + '_' + d +'.txt'
print(file_path)
# get_data
get_histry_data(file_path,k,d,2005,2020,1,1)
# Load and print saved data
data = pd.read_csv(file_path)
print(data
Acquisition of virtual currency data
The data acquisition for the virtual transit is available in a separate article, which you can read here if you are interested.
Now you can acquire millions of FX rates and build big data. We can use this data for back testing and machine learning.
If you are interested, please register with OANDA as well.
]]>0algo-ai<![CDATA[Always SSL for free “https with Nginx”]]>https://algo-ai.work/?p=24642023-01-20T04:20:21Z2023-01-20T04:20:10ZWe will introduce how to always use SSL for your website (Nginx). For HTTP, a warning is displayed in Google Chrome, so it is essential to make the website SSL-enabled. According to Google, it is written that SEO is affected by whether or not a web page is SSL-enabled. It is also stated that the quality of the certificate is currently irrelevant, so it is important for those who have a web page to convert it to SSL . Therefore, we will introduce a method to always convert to SSL for free and automatically update the SSL certificate on a regular basis.
Let’s Encrypt
Certificates are available free of charge. That is by using Let’s Encrypt. Let’s Encrypt is run by ISRG, a US non-profit organization. Since it is a certificate that can be used free of charge, people who operate web pages on their own have no choice but to use it.
Install certbot
First, install certbot. It’s easy because you can do it with one command. As a prerequisite, use the yum command on CentOS.
sudo yum -y install certbot
Create a certificate with certbot
If you can type the certbot command, you can create a certificate with the following command. Although you can enter interactively, you can also create a certificate by entering only one line. Since certbot uses port 80, if there is a web server using port 80, it is necessary to stop it in advance.
By the way, if you are using port 80, this error will occur.
Problem binding to port 80: Could not bind to IPv4 or IPv6.
The certificate will have four files in “/etc/letsencrypt/live/example.work/”. Among them, we use the following two. ・fullchain.pem: certificate ・privkey.pem: certificate private key
Change nginx settings
Set the certificate created by the certbot command to nginx. Add SSL settings to the configuration file (/etc/nginx/conf.d/default.conf, etc.). The setting addition is a setting to redirect http to https and a setting to enable access with https with the certificate created this time .
Below are additional settings.
server {
listen 80;
server_name example.work;
return 301 https://$host$request_uri;
}
server {
listen 443 ssl;
ssl_certificate /etc/letsencrypt/live/example.work/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/example.work/privkey.pem;
}
Certificate auto-renewal settings
If you can get the certificate on the command line, you can automatically update the certificate just by setting cron, and you can always support SSL. Depending on the environment, here we will set cron to execute commands as the root user. The SSL update can be done within 30 days of the expiration date, so I try to check it twice a month.
We’ve shown you how to turn your website into SSL for free. It’s easy, so if you have a web page, I think you should try it.
]]>0algo-ai<![CDATA[I let Diffusion Stable draw a picture with chat GPT]]>https://algo-ai.work/?p=24362023-01-17T05:26:01Z2023-01-17T05:19:24ZThe development of AI has been remarkable recently. I asked Diffusion Stable to draw a picture in the trendy chat GPT, and played with it. I think that usage such as giving instructions to AI with AI will continue to be popular in the future.
Ask AI for a picture that looks like a job
I couldn’t think of a picture that looks like a job, so I asked Chat GPT if there was a picture that looked like a job. He gave me four suggestions! ・Pictures like stopping a clock ・Pictures like baking bread ・ Praying hands together
I got an answer that I never thought of. it’s interesting.
ask for specifics
What is a picture that stops the clock? I asked him specifically about the first picture that would stop the clock, and instructed him to create an English sentence for Diffusion Stable to write. very. I got back a long sentence.
Here is the English translation.
“This painting depicts a young woman in a black dress standing stoically with her legs spread by a clock tower, staring into the horizon. Her face is a mask of determination. , holding the sides of the clock tower with both hands, one hand slowly reaching over the clock tower as her determined gaze is enveloped in darkness against the bleak landscape. The posture implies that she is metaphorically in a timeless space, not just in the moment, but in the larger, overarching story. We are trying to stop it in some way.”
It is a concrete content that reminds me of a woman desperately trying to stop time. Sounds like she’s the kind of woman who doesn’t want the year to end. interesting idea.
Chat uses chat GPT on slack, so if you want to play, please check it out.
I tried writing specific instructions for AI using Diffusion Stable. “Painting that looks like a job” has become “Painting that stops the clock”, creating a picture that looks like the end of the world.
It’s interesting that people can draw a picture with just a little assistance, from the word “work-like” to the AI giving specific instructions to handle AI. In the future, AI may be further hierarchized, and art may be born from hierarchical AI manipulation, such as AI instructing AI and AI operating AI according to that instruction. I think it will be a world where various things are completed. The last few years have seen the development of AI.
]]>0algo-ai<![CDATA[Run Google Colab regularly with Chrome extension]]>https://algo-ai.work/?p=24202023-01-17T05:03:41Z2023-01-17T05:00:17ZThis article is for people who want to run Google Colab regularly with Chrome extensions .
Google Colaboratory that can use GPU almost without environment construction is really amazing.
So, to get the most out of this amazing tool, we’ll show you how to run it automatically on a regular basis.
I use 3 Chrome extensions.
I also considered automatic execution with “Selenium + python”, but I could not log in to my Google account with Chrome opened as a robot browser, so I thought of another method.
Display execution time list on Google Colab
Any program can be executed periodically, but I will introduce a code that displays a list of execution times in Google Colaboratory so that you can see the time when it was executed periodically.
import datetime as dt
# Obtaining the current time
now = dt.datetime.now()
# Output current time to file
with open("./result.txt","a") as f:
f.write(str(now)+"\n")
# Output a list of execution times
with open("./result.txt","r") as f:
print(f.read())
PythonCopy
4. Press “” to execute.
If you execute it multiple times, the list of execution times will be displayed. We will run this program regularly.
Automate with UI. Vision RPA
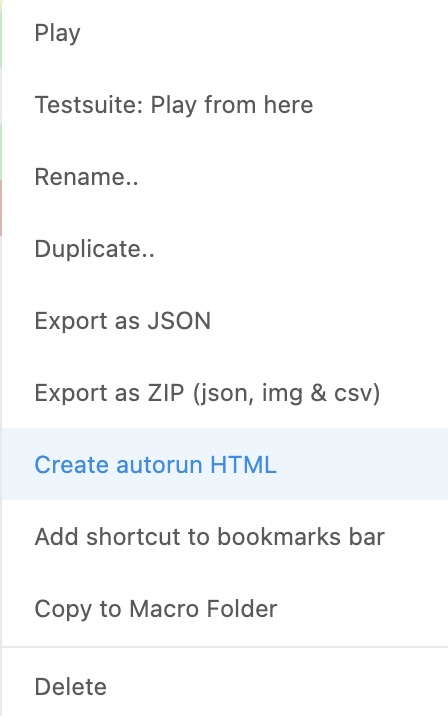
Use UI.Vision RPA to automatically operate Chrome. The procedure is as follows.
5. Click the “” button on Google Colab in chrome to record a macro.
When you run it, you can confirm that the operation is automatically recorded.
6. Click Stop Record.
7. Click “Play Macro” and confirm that it will run automatically.
8. Save the created Macro as html.
You can confirm that it is executed just by opening this saved HTML. This feature was not in Selenium, so it’s an excellent feature.
Regular execution with cronTab
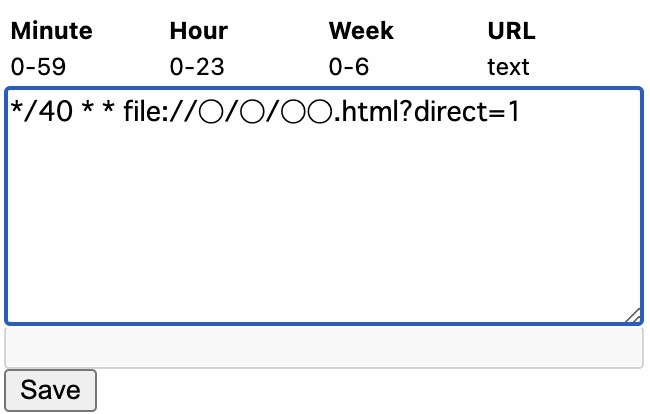
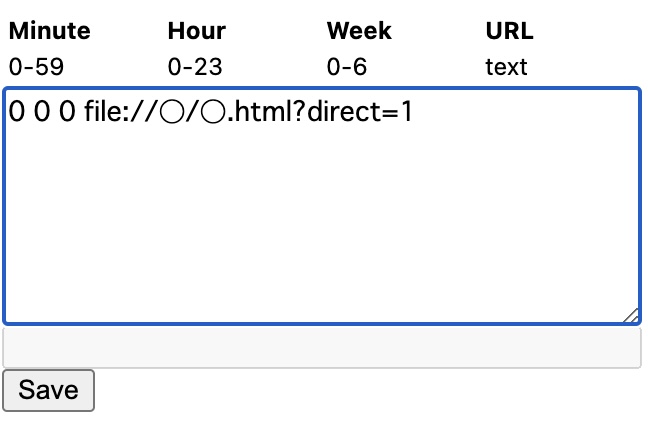
You should be able to run Google Colab just by opening the HTML file saved up to this point. After that, if the HTML file can be opened at the specified time, regular execution will be possible. The extension used there is cronTab . By using this function, you can open a specific path (URL, etc.) periodically. The procedure is as follows.
3. Make settings to open the HTML file from earlier. Enter the location (path) of the file in the URL. By adding “?direct=1” at the end here, you can eliminate the need to press “OK” after opening the HTML file and automate it. Conversely, if this postscript is not present, it is necessary to press the “OK” button, and automatic execution cannot be performed. In addition, the example below is an example of automatic execution every 2 minutes.
Automatically close tabs with Tab Wrangler
cronTab will automatically open a new tab. Therefore, tabs will be generated more and more unless they are closed automatically. So, let me show you how to automatically close tabs in Tab Wrangler.
2. Open Tab Wrangler and configure it. I think the settings are a matter of personal preference.
That’s it, you can run Google Colab regularly with just the Chrome extension. Now you can study Deep Learning regularly, and your research will progress. Of course, it is also possible to forecast time-series data on a regular basis. AlgoAI regularly predicted and tweeted time series data.
]]>0algo-ai<![CDATA[AI instructs AI to create music with Google Colab]]>https://algo-ai.work/?p=24092023-01-16T05:51:46Z2023-01-16T05:51:45ZI made music by suggesting what kind of music the chat GPT can produce with text to music. Recently, various AIs derived from text to image have appeared. text to music generates music from three tag information. In order to generate music based on this tag information, we first asked chat GPT to create a base sentence, decided tag information based on that sentence, and generated music. Chat GPT is provided by open ai, and is a next-generation AI that may be used instead of Google in Microsoft’s bing. I’m looking forward to the AI era, and I tried to touch it ahead of time.
I asked AI for a café-like song
I visited “AI’s café-like song” and asked him to give me a concrete English sentence. I asked a question using the open AI API on Slack. Chat GPT can support Japanese and speed up. The article below introduces how to use chat GPT with Slack, so please read it if you like.
He specifically taught me slow, light music. This time, we will use this character as an input character string to generate music.
text to music 「mubert」
Text to image is in vogue, but text to music is being created. You can create music from text. With mubert, you can generate music by specifying three tag information.
Using the Mubert API, get_track_by_tags determines 3 tag information from a sentence. The code was published on Google Colab. I copied and pasted the characters that chat GPT output to prompt and executed it.
I entered the characters output by Chat GPT in Prompt and executed it.
The tags of the cafe-like song were the following three.
jazz / funk
electro funk
sleepy ambient
I generated music from these three tags. duration is 60 seconds.
Conclusion
I made a café-like song concrete with chat GPT, converted it to 3 tag information, and generated non-existent music. As far as actually listening to music, text to music is still in its infancy, but I think it has great potential. By automating MIDI and lyric linkage, linking with NEUTORINO, etc., Vocaloid singing smoothly, etc., I think that if automation is developed, an integrated automatic music generation environment can be created. I’m looking forward to the world of automatic music generation in the future.
]]>0algo-ai<![CDATA[Chrome extension that automatically follows and likes Instagram]]>https://algo-ai.work/?p=24062023-01-21T07:49:44Z2023-01-16T05:23:43ZI will show you how to make Instagram auto-follow and auto-like on a regular basis with Chrome extension. People who continue to follow manually will be able to automatically follow users who post with specific tags on a regular basis. It is a method of automating with RPA, and it is a general-purpose method that can be applied. Let’s automate the browser operation and make it easier by automating what you do manually.
Chrome extension
The Chrome extensions I use are: It is a method to automatically run like & follow by opening the html file.
Superpowers for Instagram: Auto-follow and auto-like 20 users with one click
UI Vision RPA: Automate browser operations with RPA
cronTab: allows you to run commands periodically in your browser
Even if you don’t use “Superpowers for Instagram”, you can operate UI Vision RPA to make it like and follow, but it feels like it can be used as a module for more stable operation. , I decided to use it this time. It can slightly compensate for unstable operation, which is a drawback of RPA.
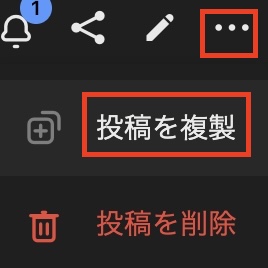
Superpowers for Instagram
Try Superpowers for Instagram. Open Instagram and open the page of the tag you want to follow or like.
As a test, open “https://www.instagram.com/explore/tags/followforfollowback/” and you’ll find a “Like all” button and a “Follow all” button. By clicking this, you can like 20 people or follow 20 people for the post of the person who posted most recently.
UI Vision RPA
UI Vision RPA can record browser operations and execute recorded records with Play Macro. Press Record and press any of the “Like all” or “Follow all” buttons in “Superpowers for Instagram” to memorize your browser actions. It can be stored in JSON format. From the next time onwards, you can execute it by pressing Play Macro. After memorizing it, check that it can be executed. When I tried it myself, I was able to get the following JSON code. You can also write this code in JSON of UI Vision RPA and execute it.
Parameters such as timeouts and command execution intervals can be set by pressing the gear settings button in UI Vision RPA. If a timeout occurs and it doesn’t work, you should increase the timeout interval or the command execution interval. Although it becomes an unstable operation peculiar to RPA, I think that it is enough if it works.
Left click on the project you are creating and select “Create autorun HTML”. You can download the HTML file. When you double-click this HTML, it will automatically like and follow. After that, if you can open this file regularly, you will be able to do regular automatic likes and follows.
cronTab
Use cronTab to open this HTML file periodically. An example of running once an hour is when Minute is divisible by 40. You can run it directly by setting direct=1. If you forget to add the option, it will not work properly. Caution is required.
With this, the html file will be opened every hour and it will be a success if you can automatically follow and like automatically.
Conclusion
In this article, we introduced how to use the Chrome extension to automatically follow and like Instagram on a regular basis. You can achieve Insta automation with the help of 3 Chrome extensions. RPA operations are difficult to stabilize, but they are versatile techniques. It can be applied to various things. We also introduce how to periodically run Google Colaboratory, which allows you to use the GPU for free, so please read it if you like.
]]>0algo-ai<![CDATA[Instagram Auto Post with Chrome Extension]]>https://algo-ai.work/?p=24032023-01-21T07:52:17Z2023-01-16T05:06:48ZI will show you how to auto post on Instagram for free. Basically, Instagram does not allow automatic posting, so we will introduce how to automatically schedule a scheduled post. If you can schedule posts automatically, you can say that you can actually post automatically. This method goes as far as automating reposting. Since RPA is used, it is possible to periodically repeat the automatic reservation of drafts created in advance in order to stabilize the operation. In the case of reposting, it is fully automatic, and if you want to make a new post, you will be able to efficiently schedule posts just by modifying the reserved ones.
How to Auto Post on Instagram
The way to automatically post on Instagram is to automate scheduled posts with RPA. Specifically, I use Statusbrew to schedule posts. For free, the maximum number of reserved posts is 10, and reposts must be manually registered. Automation is performed with the Chrome extension UI Vision RPA, and automatic booking is performed by periodically executing the operation with the Chrome extension crontab. After booking, you can modify the content of the post by editing, or you can post the draft as it is.
We also introduce how to auto-like and auto-follow, so please read it if you like.Chrome extension that automatically follows and likes InstagramIntroducing the Instagram automatic follow / automatic like function that can be used in Chrome! Easily increase your followers and likes … https://algo-ai.work/blog/2023/01/14/auto-instagram/
Instagram or Facebook must be a professional or business account. Also, it is necessary to link Instagram and Facebook in advance.
Switch Instagram to a professional account.
Click Edit Profile.
Click Switch to Pro Account to switch your account to a Pro Account.
Also, link Instagram and Facebook, and configure settings to allow linking from Instagram to Facebook and settings to allow linking from Facebook to Instagram.
From Facebook, there is an item called Instagram in the settings, and you can link it by clicking “Link Account”.
From Instagram, you can link with Facebook by clicking “Login” from the item “Linked accounts” in the settings.
In addition, Facebook also requires a business account, so click Create from the “Page” item to create a page. If you do not create a page, it will be flipped when linking with Statusbrew.
Statusbrew
Statusbrew unifies content marketing management for social media, risk management measures, engagement management including comment monitoring, optimizes internal approval workflows, and enables high-performance analysis. In the free version, you can schedule posts, define categories, define plans, etc. In addition, you can easily post one post to multiple SNS such as Twitter, Facebook, and Instagram. This time, I will use it for the purpose of posting on Instagram.
Create a user and log in to create a space. Enter any name and click “Create”.
You can connect social profiles by creating a space and selecting the created space. Click Instagram.
I clicked on “Login via Facebook”.
Allow Statusbrew from the app and website in your Instagram settings.
It will be a success if we can cooperate safely.
How to use Statusbrew
I thought Statusbrew would take some getting used to.
You can access the top page by logging in and pressing the logo on the top left. In the free version, you can set calendar and category posts.
You can schedule posts on the calendar, and you can set a schedule pattern to use on the calendar for category posts. If you use this category post well, you can efficiently set up reservations.
Category post
For category posts, you can assign a category name and create a reservation pattern.
For example, if you set it as follows, it is a pattern that can be set so that the same post can be made at 6:45 in the morning on Monday, Wednesday, and Friday. It can be patterned and, if used well, can be efficient.
It is convenient when making a reservation if you use a name that is easy to understand.
Post draft
Create drafts instead of direct bookings for automation. I’m ready to duplicate the draft and schedule it.
Click the paper plane icon on the left and select Drafts.
Click Create Post.
Enter your social profile, text, and upload the photos you want to subscribe to on Instagram. Since it is a regular reservation, you can replace the photo after making a reservation. Check “Add Draft”.
In Category Reserve, select the category you created. It’s nice because you can make a pattern reservation instead of the date and time.
Click the Add Draft button to create a draft. In preparation, you will create multiple drafts of this. Up to 10 items can be reserved at once in the free version. With the method introduced in this article, you can make a free and flexible fully automatic reservation by creating a category for each month to day. I’m going to be so detailed, so I tried to create it all together for the time being. I thought that it would be enough to make an automatic reservation about twice a week.
Install Chrome extension
For automation, we use the Chrome extension UI Vision RPA and crontab. It is an RPA tool that can automate Chrome operations and a tool that can be regularly executed with pre-scheduled content.
Duplicate drafts in UI Vision RPA for automatic booking.
Open UI Vision RPA and click the “+Macro” button to create a new macro.
Click the “Record” button to let Statusbrew automate and record Chrome activity.
Specifically, on the draft screen, click the draft you created, click “…”, and select “Duplicate Post”.
When the screen changes, perform the operations up to posting and have RPA remember it. Uncheck “Add Draft”, select “No Approval” in the “Assign Approver” item, and click “Reserve Post” to complete. It won’t be posted right away, so press Scheduled Post to test it. When done, press the UI Vision RPA’s “Stop” button to end the Record.
I was able to record the operation with UI Vision RPA. Run “Play Macro” to see if it works. I have a macro that can repost if it works properly.
Convert macro to HTML
UI Vision RPA can be downloaded in HTML format.
Right-click the macro you created and select Create autorun HTML.
You can download the html file by selecting it. From now on, you can run the recorded macro simply by opening this HTML file.
Periodic execution
Regular execution is executed with crontab of chrome extension. Up to this point, just by opening the HTML file, you can duplicate the draft and schedule posting.
Open Chrome’s crontab and schedule it for regular execution.
Use the URL displayed in chrome when executing the html downloaded with the RPA tool. Add “?direct=1” and set it. In the following case, we are scheduling to directly open the RPA html at 00:00 on Sunday. The option is set to open directly with “?direct=1”. It doesn’t work without settings. Caution is required.
With this, you can regularly schedule posts on Mondays, Wednesdays, and Fridays at 00:00 every Sunday. Since the categories were grouped together, the schedule was rough, but if you set it in detail, you can automate the reposting of different images every day. By creating RPA, it may be possible to replace images.
Conclusion
I introduced how to automatically post by making an automatic reservation on Instagram for free. Auto-posting on Instagram is considered bad, but I don’t think there’s a problem with auto-booking. I think it would be a good idea to make an automatic reservation, basically change the image if you have time, and automatically repost the image that was viewed most often in the past when you don’t have time. .
]]>0algo-ai<![CDATA[Try waifu on M1 MAC]]>https://algo-ai.work/?p=23812023-01-16T04:16:42Z2023-01-16T03:03:45ZI will show you how to use Waifu easily without programming on M1 MAC. Waifu is an image generation AI model that specializes in 2D paintings. I will show you how to use it easily without any difficulty. By specifying a custom model in Diffusion Stable, you can easily use it in the GUI.
Install Diffusion Bee
How to install Diffusion Bee is introduced in the past article. We have also introduced how to use a custom model, so this time just select WAIFU and use it.
ckpt file and download it. This ckpt file will be the AI model. In addition to WAIFU, many ckpt files are open to the public.
Select WAIFU
Start Diffusion Be, click the three lines in the upper right and select Setting. There is a Custom Models column in Settings, so you can easily try WAIFU by clicking Add New Model and selecting the ckpt file you downloaded earlier.
Press the Generate button to create the image.
List of models
A list of CKPT files. Since Stable Diffusion is an OSS, it’s amazing how democratized it is. I can’t wait to see how AI develops in the next few years.
]]>0algo-ai<![CDATA[Make chat GPT available in slack]]>https://algo-ai.work/?p=22812023-01-11T07:40:15Z2023-01-12T07:28:00ZChat GPT is a hot topic as a chat bot that is too smart. We will introduce how to implement it with slack so that you can easily use it in your work. If you can consult on slack, there is no doubt that the work of the team will progress.
How to get OpenAI API key
Get your OpenAI API key and get ready for server-side scripting.
Sign up and log in below. You can also register with a Google Account.
In the script, write down the character strings for [Your own OpenAI API key] and [Your own Slack Incomming URL]. The Slack URL will be explained in the next section on how to get it.
function doPost(e)
{
var params = JSON.parse(e.postData.getDataAsString());
if('challenge' in params)
{
return ContentService.createTextOutput(params.challenge);
}
var userName = params.event.user;
var textSlack = params.event.text.substr(0, params.event.text.length);
var resultStr = getChatGptMessage(textSlack);
var contents = `<@${userName}> ${resultStr}`;
var options =
{
"method" : "post",
"contentType" : "application/json",
"payload" : JSON.stringify(
{
"text" : contents,
link_names: 1
}
)
};
UrlFetchApp.fetch("https://hooks.slack.com/services/[自身のSlack IncommingのURL]", options);
}
function getChatGptMessage(message) {
var uri = 'https://api.openai.com/v1/completions';
var headers = {
'Authorization': 'Bearer [自身のOpenAIのAPIキー]',
'Content-type': 'application/json',
'X-Slack-No-Retry': 1
};
var options = {
'muteHttpExceptions' : true,
'headers': headers,
'method': 'POST',
'payload': JSON.stringify({
"model": "text-davinci-003",
"max_tokens" : 2500,
"prompt": message})
};
try {
const response = UrlFetchApp.fetch(uri, options);
var json=JSON.parse(response.getContentText());
return json["choices"][0]["text"];
} catch(e) {
console.log('error');
}
}
JavaScriptCopy
After creating the script, click New Deploy, click the gear and select Web app. For Who has, select anyone and click Deploy. Login and authorize with Authorized access.
Click Deploy to create a Web URL, copy it.
Create a Slack app
Login to slack and go to slack app directory. Select Build on the top right.
Select Create an app to create your App.
Select From scratch and create with scratch.
Enter the App Name with any character string and select the channel to add the created App. Click Create App.
Select Incoming Webhooks and get the URL to receive from Google Apps Script.
Set Activate Incoming Webhooks to “On”.
Copy the WebhookURL and paste it into the Google App Script script created in the previous section.
Select Event Subscriptions from the left sidebar.
Enter the URL to send from Slack to the Google Apps Script side server. A parameter including challenge is sent to the Google Apps Script Post function and checked.
If you can connect properly with both Google Apps Script and Slack’s Event Subscriptions, you can use chat GPT with slack.
Finally
I introduced how to make chat GPT touchable with slack. If you are using slack for business, you will be able to use chat GPT as a consultant and your work will progress. Not only that, chatting will become more active, and organizational strength may increase. Please try using it.
We also have an article on how to use chat GPT on LINE. If you are interested, please read along.
]]>0algo-ai<![CDATA[Get cryptocurrency price]]>https://algo-ai.work/?p=21502023-01-11T00:52:05Z2023-01-10T15:07:04ZThis article is for those who want to get the price of virtual currency with Python . I will publish my own code, so you can copy and paste it to Google Colab and run it as it is.
code
It will be the whole code. If you only need the code, you can copy and paste it to GoogleColab and execute it to get the price of the virtual currency and output it to a file. It is also possible to get multiple values by changing only the parameters.
# Install library to use bitmex API
!pip install ccxt
# coding:utf-8
import ccxt
import pandas as pd
from datetime import datetime, timedelta
import pytz
# Specify where to save the file
file_path = './vc_data.csv'
# Number of data you want
data_volume = 1000
# Specify the type, duration, and number of data to be acquired
vckind = 'BTC/USD'
vcduration = '1d' #'1h','5m','1m'
def get_virtual_currency(file_path,data_volume,vckind,vcduration):
bitmex = ccxt.bitmex()
# Get current time on bitmex
now_time = bitmex.fetch_ticker(vckind)['timestamp']
# Calculate the number of data acquired
from_time_difference = 0
if(vcduration == '1d'):
from_time_difference = 24 * 3600 * data_volume
elif(vcduration == '1h'):
from_time_difference = 3600 * data_volume
elif(vcduration == '5m'):
from_time_difference = 60 * 5 * data_volume
elif(vcduration == '1m'):
from_time_difference = 60 * 1 * data_volume
# Specify the data time you wish to retrieve. Multiply by 1000 for milliseconds.
from_time = now_time - from_time_difference * 1000
# Get Data
candles = bitmex.fetch_ohlcv(vckind, timeframe = vcduration, limit=1000,since = from_time)
# Formatting data with column names(unixtime,open,high,low,close,volume)
res = pd.DataFrame(None)
r = pd.DataFrame(candles)
res['time'] = r[0].apply(lambda d:datetime.fromtimestamp(int(d/1000)))
res['time'] = res['time'].apply(lambda d:pytz.utc.localize(d).astimezone(pytz.timezone("Asia/Tokyo")))
res['time'] = res['time'].apply(lambda d:d.strftime('%Y/%m/%d %H:%M:%S'))
res['open'],res['high'],res['low'],res['close'],res['volume'] = r[1],r[2],r[3],r[4],r[5]
# Save formatted data in csv (exclude index information as it is unnecessary)
res.to_csv(file_path,index=0)
res = pd.DataFrame(None)
r = pd.DataFrame(None)
# main
# Retrieve virtual transit data and save to file_path
get_virtual_currency(file_path,data_volume,vckind,vcduration)
# Load and print saved data
data = pd.read_csv(file_path)
print(data)
How to use the code
Lines 9 to 15 specify the parameters for the acquired data.
By changing this parameter, you can get the price of various cryptocurrencies up to the current price.
file_path: csv save destination of acquired data (Google Drive path is also possible)
data_volume: number of rows of data to retrieve
vkind: the type of data to retrieve
vcduration: Interval of data to retrieve
By executing this parameter on line 55, you can get virtual currency data and output a file.
I think that it is better to have many types of data when building AI for automatic trading. Let’s get the data that can be automatically acquired. However, if you make a request with a high frequency, it will be regarded as a DDOS attack and an error will occur. So I try to request it at regular intervals.
import time
# Set parameters together
data_volume = 1000
vckind = ['BTC/USD', 'ETH/USD' ,'XRP/USD']
vcduration = ['1d','1h','5m','1m']
# Data acquisition based on each parameter
for kind in vckind:
for duration in vcduration:
file_path = './vc_data'+'_'+kind.replace('/','_')+'_'+duration.replace('/','_')+'.csv'
get_virtual_currency(file_path,data_volume,kind,duration)
# Loading Saved Data
data = pd.read_csv(file_path)
print(file_path)
print(data)
# Sleep to avoid being considered a DDOS attack
time.sleep(1)
time.sleep(10)
Finally
Now you can get the data of the virtual transit. I would like to proceed with technical analysis and machine learning based on this data.








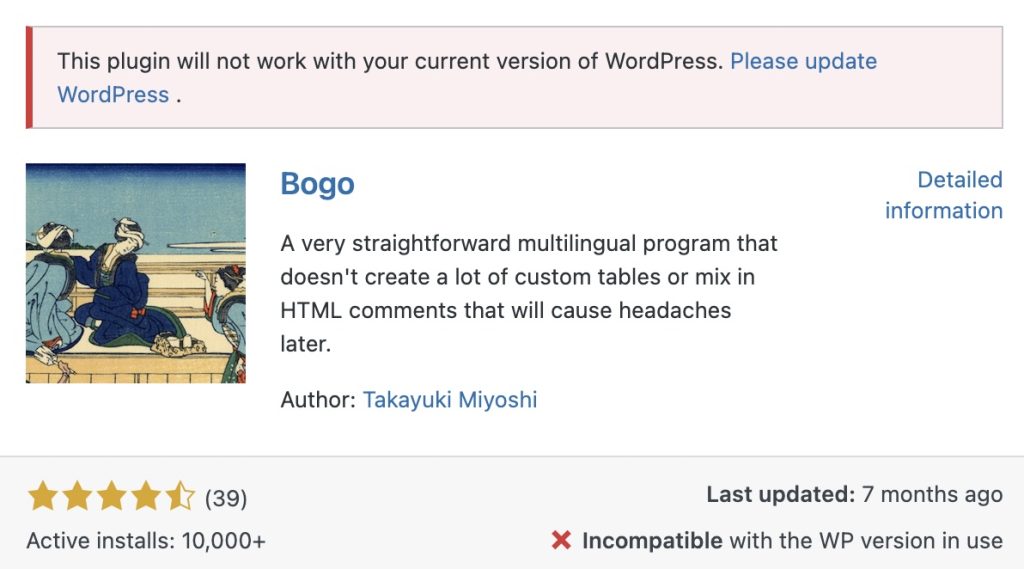





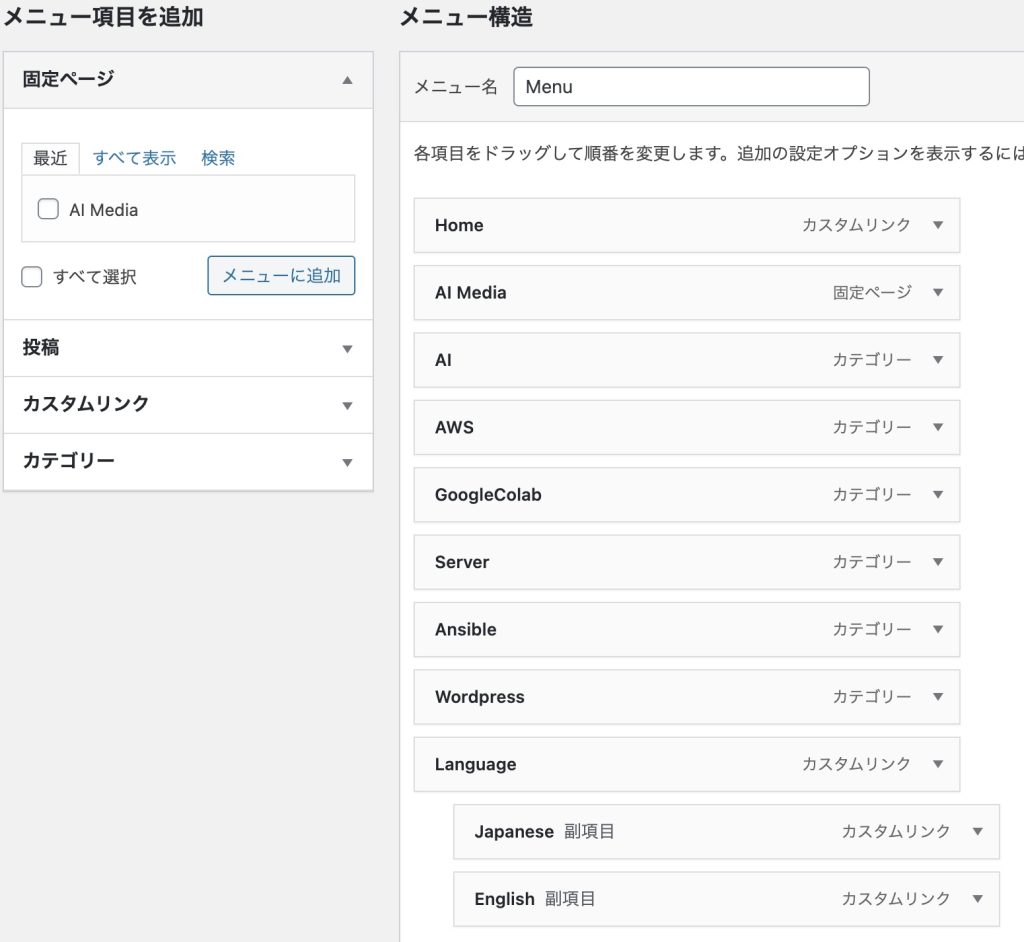
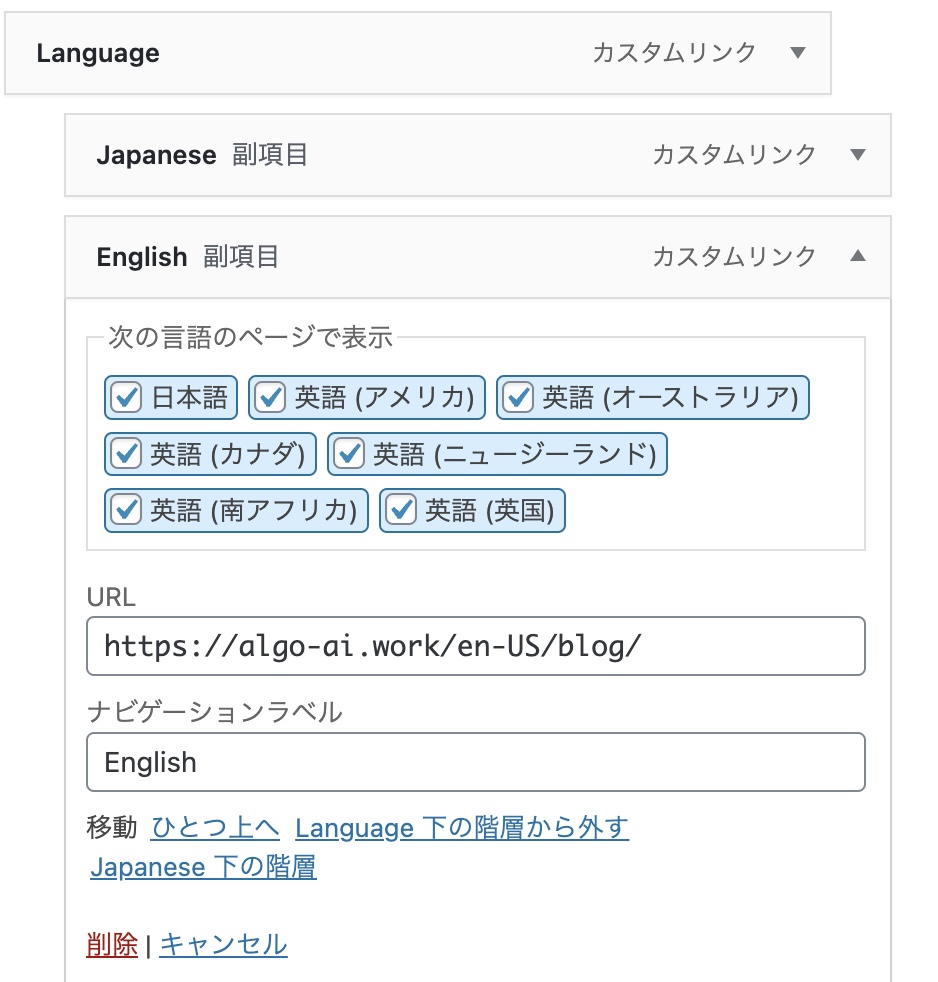






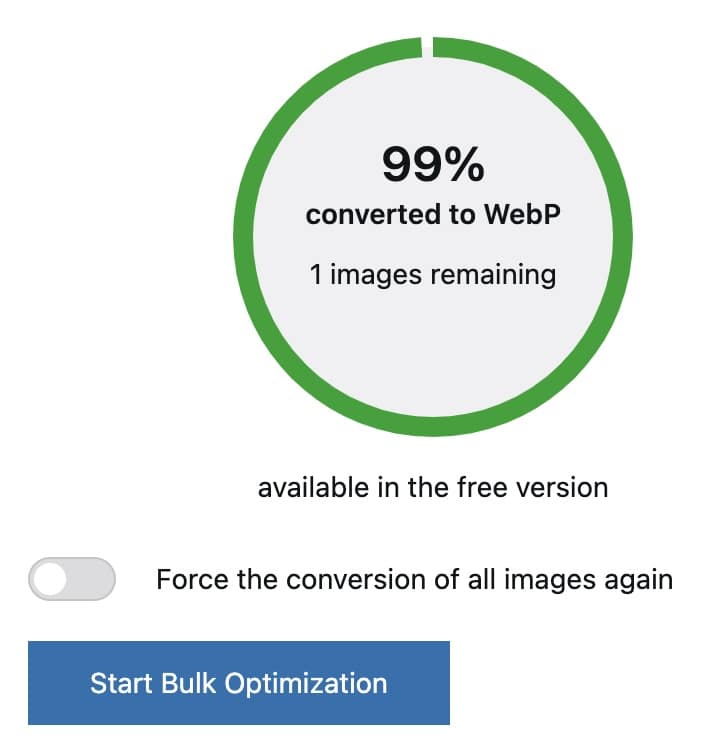

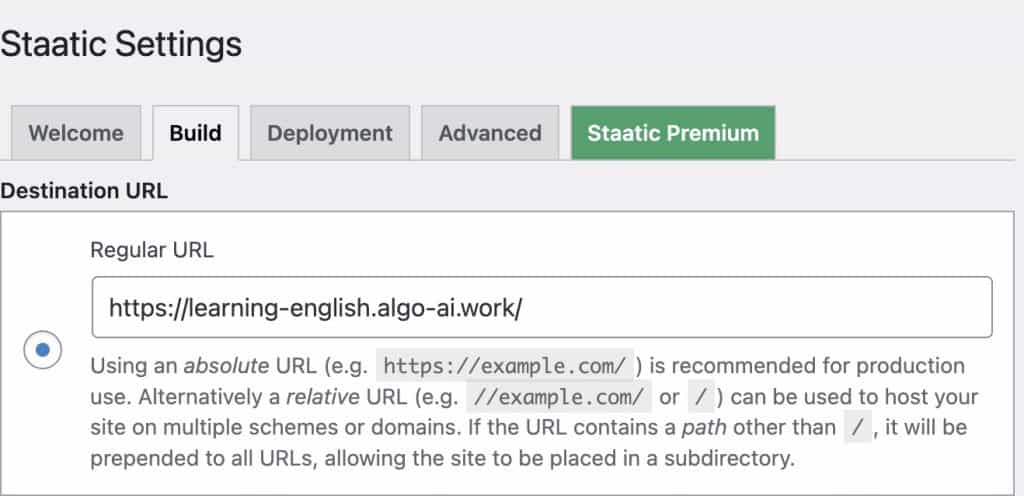


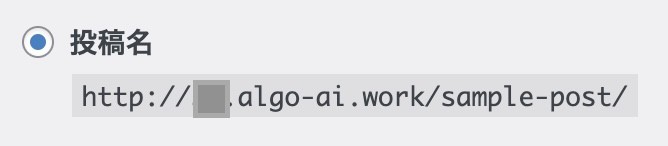


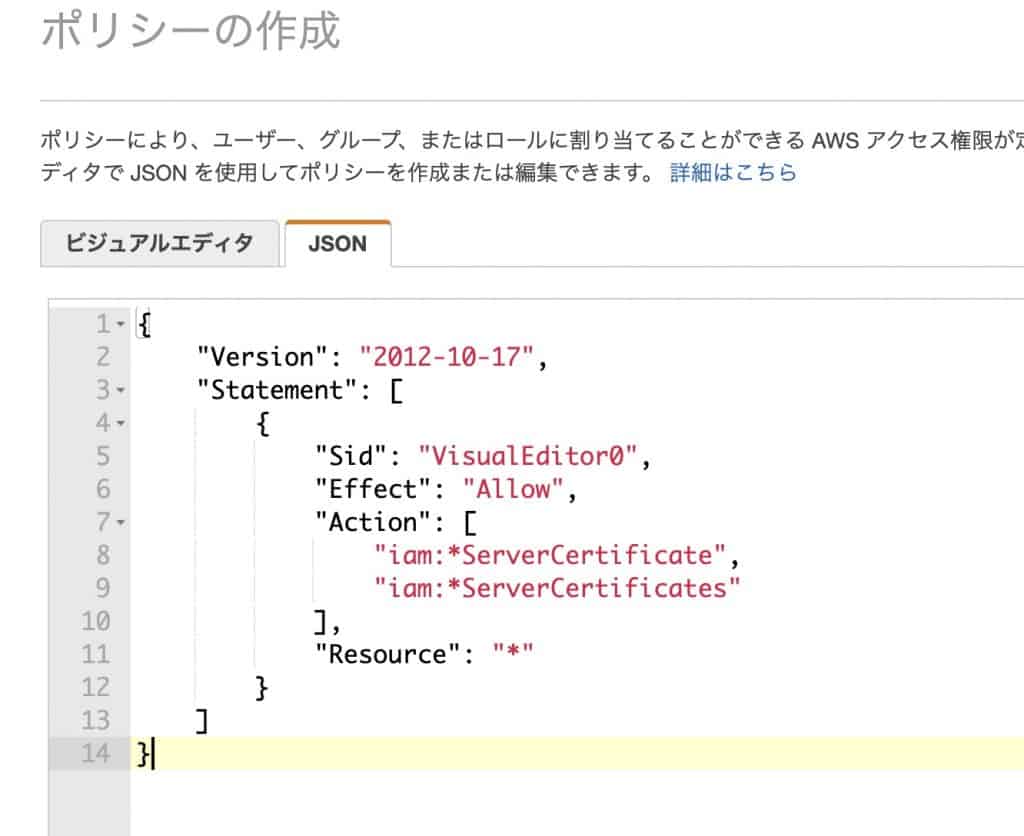

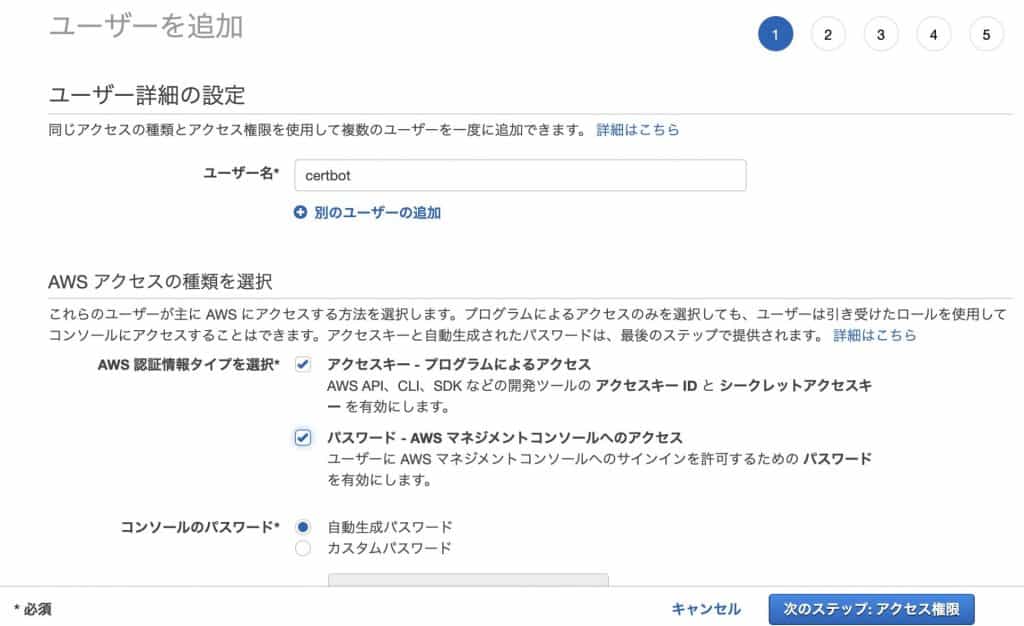



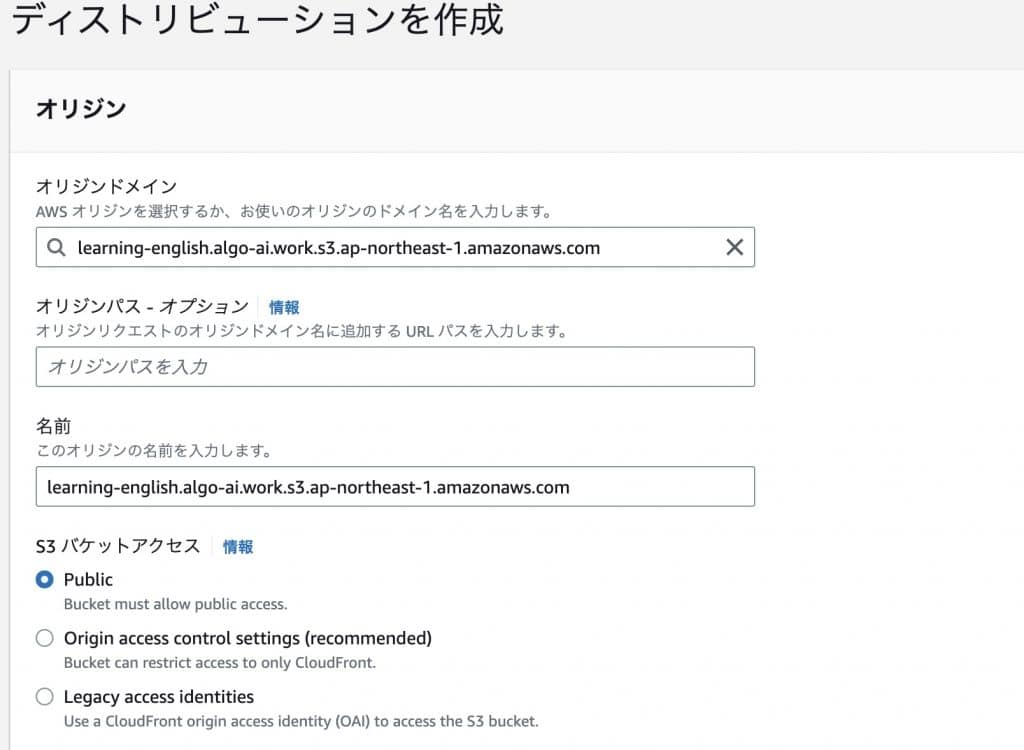
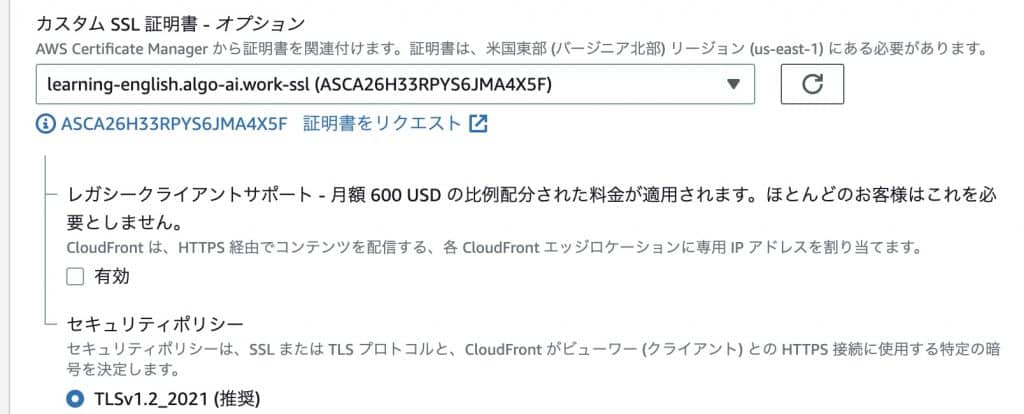
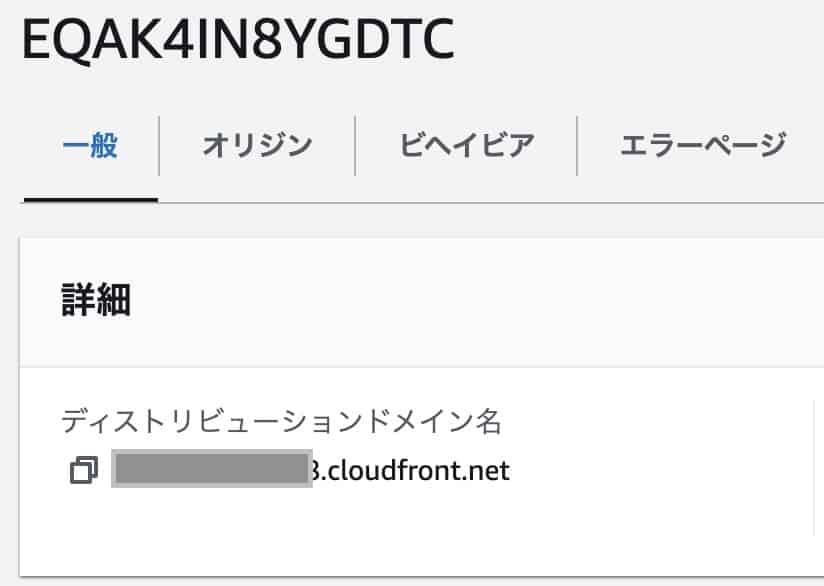
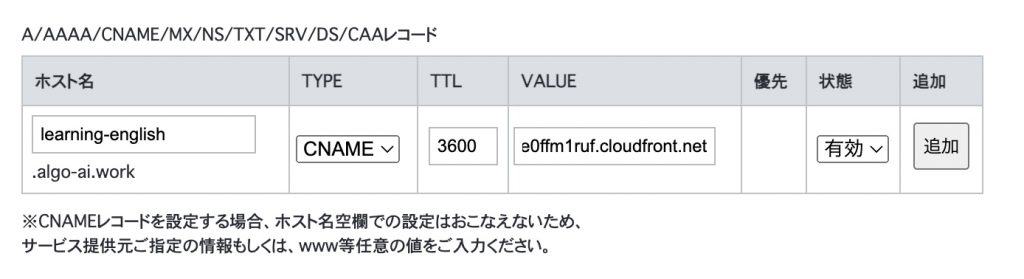




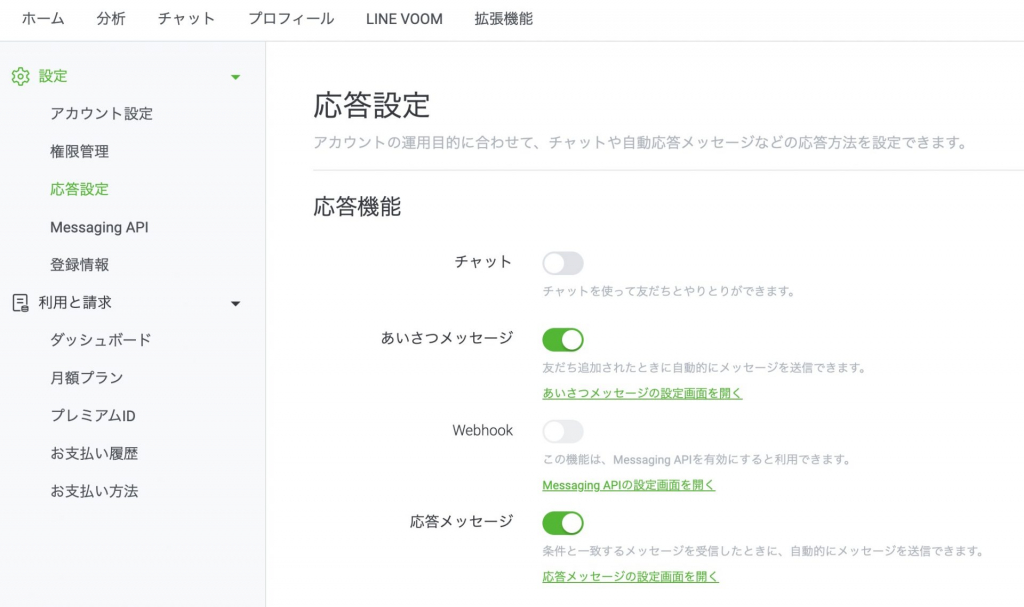
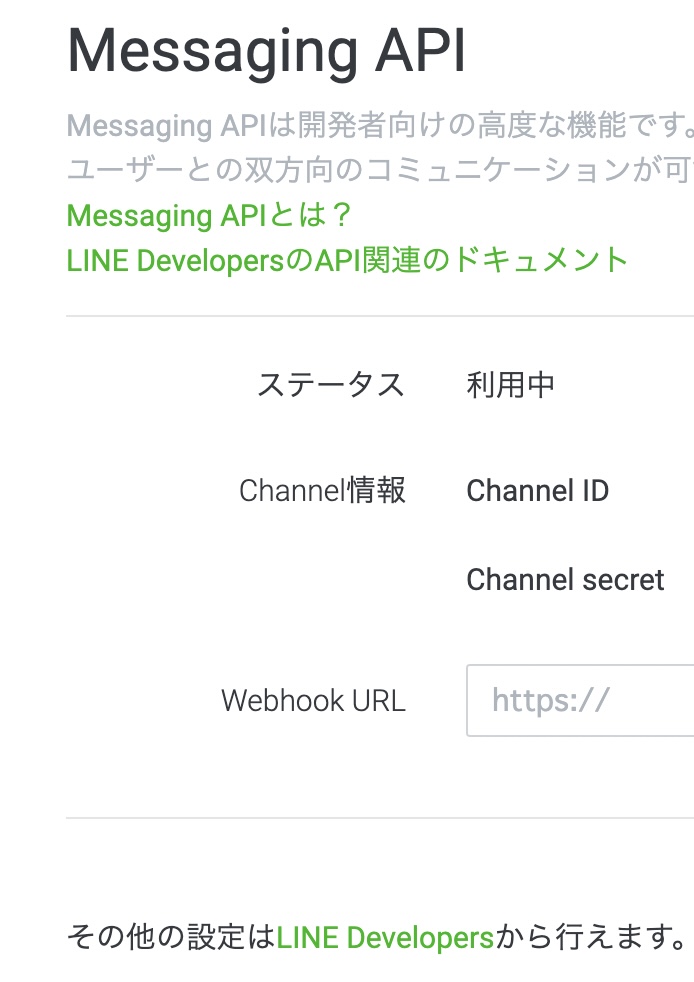


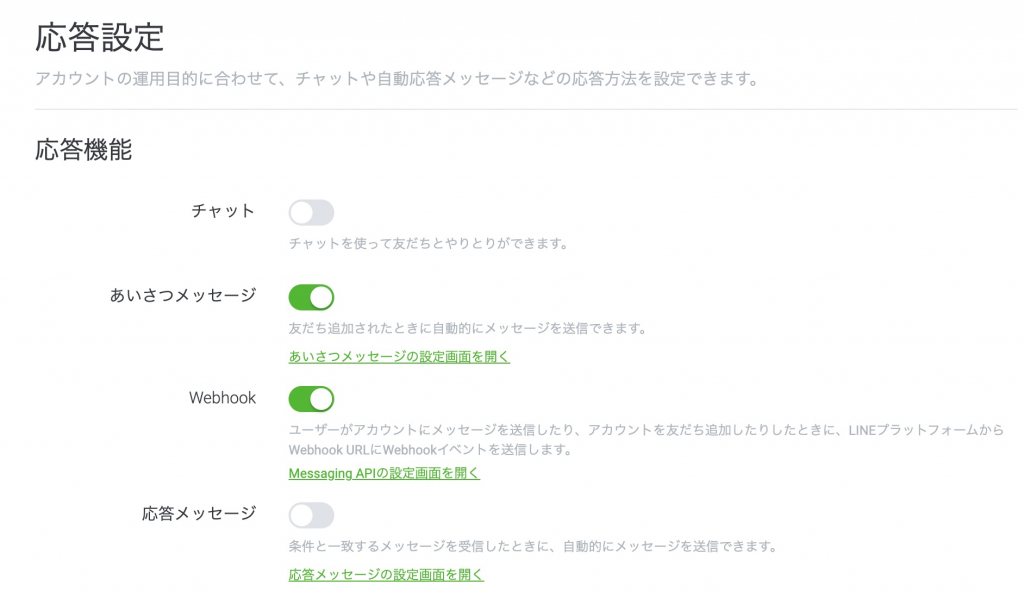













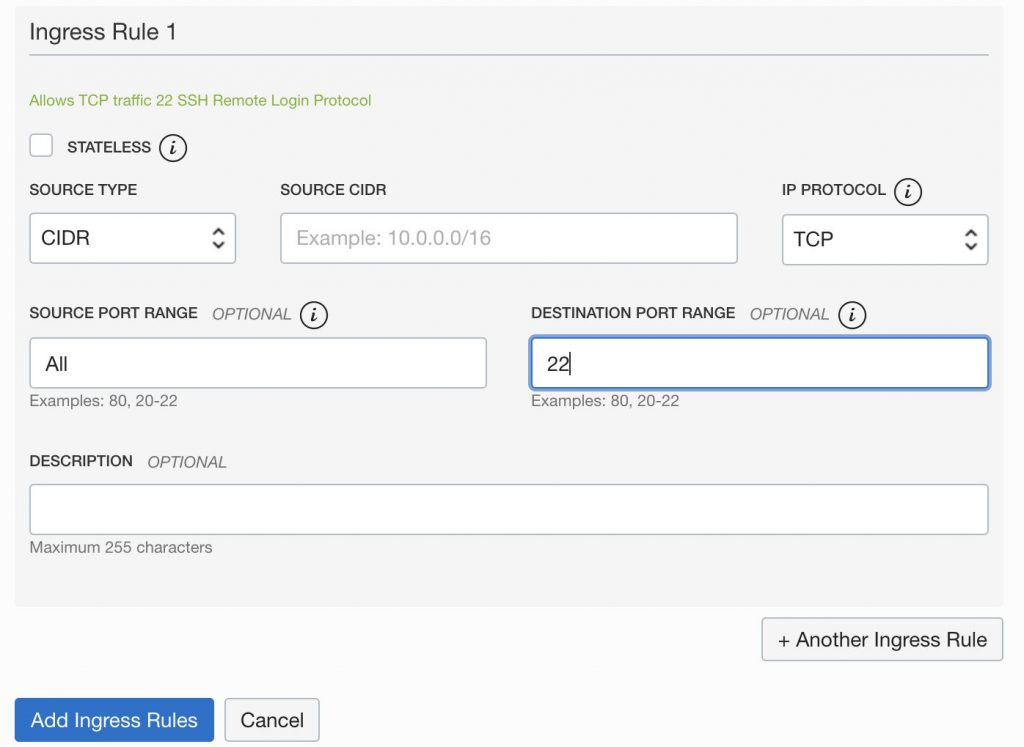
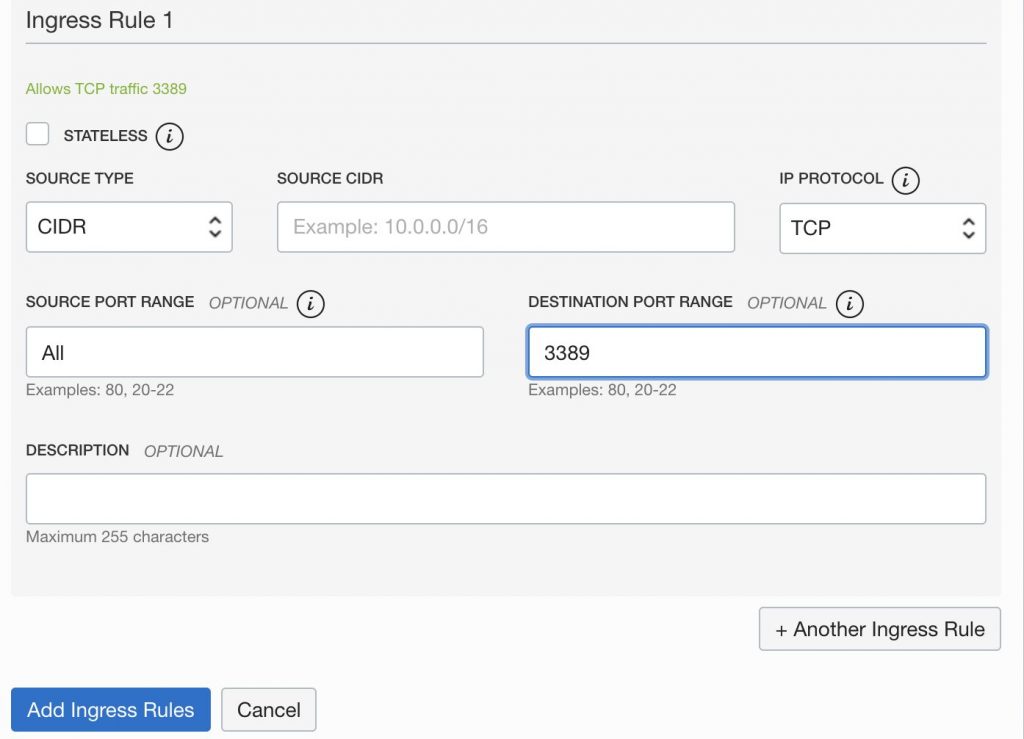


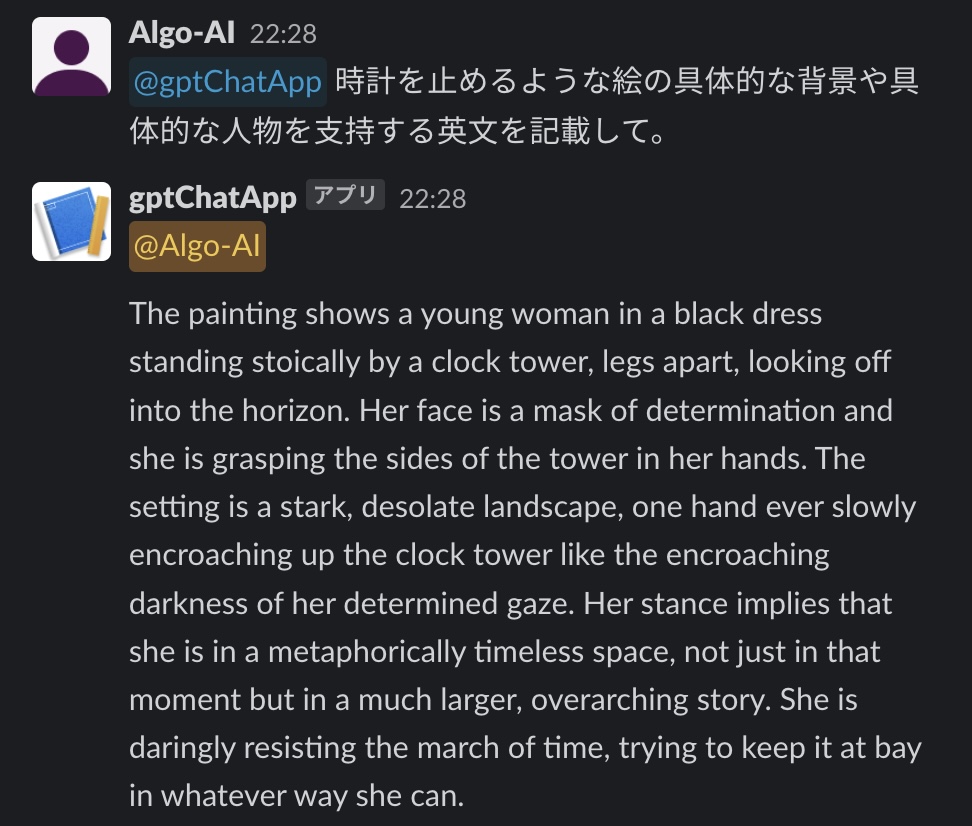

 ” to execute.
” to execute.