イベント概要と主要な発表内容
OpenAIは2025年10月6日、米サンフランシスコのFort Masonで開発者向けカンファレンス「DevDay 2025」を開催しました。CEOサム・アルトマン氏がスタートしたキーノートでは、最新の研究成果や製品発表が続々と披露され、AI業界に大きなインパクトを与えました。特に注目すべきは、次世代の言語モデル「GPT-5」および高性能版「GPT-5 Pro」の正式発表でした。また、ChatGPT内で動作するアプリケーション(Apps)の登場や、その開発キット「Apps SDK」の提供も大きな話題でした。さらに、OpenAIはAMD社との戦略的提携によるAIチップ供給契約や、動画生成モデル「Sora 2」のAPI提供開始など、開発者エコシステムを強化するための複数の発表を行いました。これらの発表は、OpenAIが開発者により強力で便利なツールを提供し、AIをより身近に使える環境づくりを加速させようとする戦略を明確にしたものです。
DevDay 2025での主要な発表内容を以下にまとめます。
- 次世代モデル「GPT-5」と「GPT-5 Pro」の発表:ChatGPTに新モデルGPT-5が搭載され、さらに高度な「GPT-5 Pro」がProプランで提供される。GPT-5は従来モデルを上回るスピードと精度を備え、特に専門領域や難易度の高いタスクで優れた性能を示す。
- ChatGPT内で動作する「Apps」と「Apps SDK」の提供:ChatGPTにアプリケーション(アプリ)を組み込める新機能が追加され、SpotifyやZillow、Canvaなどのサービスがすでに連携可能になった。開発者向けにはApps SDKが提供され、ChatGPT上で外部ツールやデータを接続して独自アプリを構築できるようになる。
- 音声対話モデルの強化とマルチモーダル対応:より安価で高速な音声対話モデル「gpt-realtime mini」がAPIに追加され、低遅延のストリーミング音声応答を実現。また、ChatGPTはテキスト・画像・音声を含むマルチモーダルな対話に対応しつつあり、今後は会話だけでなく音声でのインタラクションが主要な利用形態になると指摘された。
- 開発者向けツールの充実:Agent Builderと呼ばれるエージェント構築ツールが公開され、ビジュアルインターフェースでAIエージェントを作成できるようになる。また、APIの大幅な改善(モデルの追加や応答速度向上、機能呼び出しの安定化など)が発表され、開発者はより高度なAIアプリケーションを構築しやすくなる。さらに、コード生成モデルの「Codium」がChatGPT内で利用可能になり、ソフトウェア開発の効率化が図られる。
- AMDとの提携によるインフラ強化:OpenAIはAMD社と戦略的提携を締結し、今後数年間で合計6ギガワット分のAIチップ(AMD Instinct GPU)を供給してもらう契約を結びました。これにより、OpenAIはNVIDIAに頼らない独自の計算基盤を強化し、モデル訓練やサービス提供のスケーラビリティを高めることが期待されます。
- 動画生成モデル「Sora 2」の公開:OpenAIが開発したテキストから動画を生成する次世代モデル「Sora 2」が発表され、APIでプレビュー提供が開始されました。Sora 2は従来モデルに比べ、より写実的で物理的に整合性のある映像を生成し、音声との同期も高度に行えるなど、動画生成AIの新たなハイレベルを示します。
これらの発表内容は、OpenAIが開発者コミュニティへの開放とツール提供を加速し、AI技術をより幅広い用途に活用できるようにする戦略を鮮明にしたものです。次章以降では、各発表内容を詳しく解説します。
GPT-5 とモデルアップデートの詳細
DevDay 2025で最大の注目を集めたのが、OpenAIの最新言語モデル「GPT-5」およびその高性能版「GPT-5 Pro」の正式公開です。GPT-5はChatGPTにおいて新たな標準モデルとして搭載され、既存のGPT-4系モデルに代わる次世代のAIとなります。さらに、より高度な推論能力が必要なユースケース向けに「GPT-5 Pro」が用意され、ChatGPT Proプランのユーザーが利用できるようになりました。ここでは、GPT-5および関連モデルの特徴や改良点、そして他モデルとの比較について詳しく解説します。
GPT-5の特徴と改良点
GPT-5は、OpenAIがこれまで公開してきたGPTシリーズの最新版であり、汎用的かつ強力な汎用言語モデルとして位置付けられています。GPT-5は従来のGPT-4やその派生モデル(例えば、2024年に登場したマルチモーダル対応のGPT-4oなど)を大きく上回る性能を備えています。特に、応答のスピードと精度が向上しており、複雑な質問に対してもより迅速かつ正確に答えることができます。OpenAIによれば、GPT-5は従来モデルより総合的に「賢く」、数学・科学・金融・法律・医学など様々な分野でより有用な回答を提供するとされています。
GPT-5の改良点の一つは、長大なコンテキストの処理能力です。GPT-5は最大で40万トークンもの長い入力を扱えるとされ、従来のGPT-4(最大32kトークン程度)に比べ桁違いの長文処理が可能です。これにより、ユーザーは数百ページに及ぶ文書や大量のデータを一度に渡して要約・分析させることも現実的になりました。また、出力も最大128kトークンに拡大されており、非常に長い文章の生成や詳細なレポート作成も可能です。このような長大なコンテキストウィンドウにより、より文脈を踏まえた高度な対話や、大規模データセットの理解・要約が実現しています。
さらに、GPT-5は推論速度の高速化も図られています。OpenAIによれば、GPT-5は同じ回答を得るのに従来モデルより少ないトークン数で済み、処理が効率化されているとのことです。実際、GPT-5は同じ質問に対してGPT-4oやo3モデルよりも短い応答で必要な情報を提供できる傾向があり、ユーザーはより迅速に結果を得られます。この高速化は、特にリアルタイム対話や大量のデータ処理が必要な用途で有用です。
加えて、GPT-5は安全対策や事実性の向上も図られています。OpenAIはGPT-5において「最も信頼性と事実性の高いモデル」と謳っており、誤情報の生成(幻覚)を抑制するよう訓練されています。実際、GPT-5は公開されたプロンプトに対する幻覚率が1%未満と非常に低く、難しい医療の質問に対しても誤答率が1.6%に抑えられているとの報告があります。これは、GPT-4oなどの旧モデルに比べ大幅な改善であり、医療や法務のような高精度が求められる分野での利用にも耐えうる水準と言えます。
GPT-5 Proとその差別化
GPT-5 Proは、GPT-5の上位モデルとして提供される高性能バージョンです。ChatGPTの有料プラン「ChatGPT Pro」に加入しているユーザーが利用可能であり、より高度な推論や専門領域での応答に特化しています。GPT-5 Proは、通常のGPT-5よりも計算資源を多く割り当ててより深い思考(チェイン・オブ・ソート)を行えるモードを備えています。そのため、難易度の高い問題や複雑な分析タスクではGPT-5よりも高精度な結果を導き出せる傾向があります。
GPT-5 Proの主な特徴として、より高度な推論と専門性が挙げられます。例えば、高度な数学問題や論理的思考を要する質問に対して、GPT-5 Proはより深い思考プロセスを踏んで回答することで正答率を高めます。実際のベンチマークでも、GPT-5 Pro(Pythonツール併用)はPhDレベルの科学質問に対して89.4%という高い正答率を記録し、GPT-5標準モードの87.3%を上回っています。また、GPT-5 Proは長大な推論過程を保持し続ける能力に優れており、複数ステップにわたる問題解決や、長い対話の文脈を綿密に追跡することが得意です。このため、金融分析や法律文書のレビュー、医療診断の補助など、高い信頼性と深い分析が求められる用途でGPT-5 Proは威力を発揮します。
一方で、GPT-5 Proは高性能ゆえに応答速度が通常モードより遅くなる傾向があります。高度な推論を行う分、計算に時間がかかるためです。例えば、同じSQLクエリ生成タスクでは、GPT-5標準が平均113.7秒かかったのに対し、Googleの競合モデル(Gemini 2.5 Pro)はより高速だったとの報告もあります。このように、GPT-5 Proは「精度 vs. 速度」のトレードオフがあり、用途に応じて使い分けることが推奨されます。日常的な対話や軽い質問にはGPT-5標準モードで十分な場合が多く、高度な分析が必要な際にのみGPT-5 Proを使う、といった使い方が想定されています。
なお、GPT-5 ProはChatGPTのProプランユーザー向けに提供されるため、API経由では利用できない点にも注意が必要です。OpenAIは企業や開発者向けに別途「GPT-5 Pro API」を用意しており、より高いトークン処理能力や長いコンテキストを利用可能にしています。ただしその費用は高額(1分あたり数百ドル規模)との報道もあり、一般ユーザーではなく特定の専門ユースケース向けのサービスとなっています。
oシリーズモデル(o3)の概要
DevDay 2025では、新モデルGPT-5の登場に合わせて従来のモデル体系も刷新されました。特に注目すべきは、OpenAIがこれまで内部で開発していた「oシリーズ」モデルの扱いです。oシリーズとは、OpenAIがGPT-4の後継として検討していた高度な推論モデルであり、「o」は「omni(全般的)」や「oracle(予言者)」を意味するとも言われます。2024年にはマルチモーダル対応のGPT-4oが公開され、テキストと画像を理解・生成できるモデルとして話題を呼びました。さらにその後、より推論能力を高めた「o3」モデルが開発され、一部のベータ版ユーザーに提供されていました。
o3モデルは、GPT-4oより高度な推論力と長大なコンテキスト処理を謳うモデルでした。実際、o3は最大100万トークンものコンテキストを扱えるとされ、その膨大な長文処理能力は業界をリードするものでした。また、推論精度の面でもGPT-4oを上回り、専門分野の質問に対する正答率が高かったと報じられています。o3は「ChatGPT-4 Pro」とも呼ばれ、OpenAIの招待を受けた一部ユーザーが月額200ドルで利用できるプレミアムサービスとして提供されていました。このサービスでは、ユーザーはo3モデルを用いて高度な分析や長文要約を行えましたが、その高価格帯ゆえ一般的な利用には限られていました。
DevDay 2025では、このoシリーズの開発は一段落し、その技術が新たなGPT-5に統合された形となります。OpenAIは「GPT-5はoシリーズを凌駕する汎用モデル」として紹介しており、今後はGPT-5およびGPT-5 Proが主要なモデルとなる方針です。実際、GPT-5は長大なコンテキスト処理や高度な推論能力といったo3の強みを多く取り込んでおり、一部の報道ではGPT-5は「GPT-4oとo3を統合したモデル」とも評されています。一方で、o3モデル自体は今後公式には提供されなくなる見込みですが、その技術要素はOpenAIの他のサービスやバックエンドで活用されていくと考えられます。
モデル間の比較と評価
OpenAIの2025年時点のモデル群(GPT-5、GPT-5 Pro、GPT-4o、o3など)は、それぞれ異なる特徴と得意分野を持っています。以下の図は、これら主要モデルのベンチマーク結果を比較したものです。Data Source:
上記の比較から、GPT-5およびGPT-5 Proは総合的に最高水準の性能を示していることがわかります。特に専門分野の高度な質問やコード生成タスクでは、GPT-5/ProはGPT-4oや旧来のGPT-4を大きく凌駕しています。 また、GPT-5 ProはGPT-5標準よりもわずかに高い正答率を記録しており、難問への対処に優れていることが確認できます。一方、o3モデルはGPT-4oよりも優れた性能を示しましたが、GPT-5に比べるとやや遜色があります。特にコード生成分野では、GPT-5(Thinkingモード)の74.9%に対しo3は69.1%と、GPT-5が上回っています。このことから、OpenAIはGPT-5の登場によってモデルラインナップを整理し、新モデルに統合することで開発者やユーザーの混乱を減らそうとしていると考えられます。
ユーザーや開発者にとって、これらモデルを使い分けるポイントはタスクの難易度と用途です。日常的なチャットや一般的な質問には、無料版や標準のGPT-5モードで十分な場合が多いです。一方、高度な専門知識を要する分析や非常に長大な文書の要約・検証を行う場合には、GPT-5 Proや長大コンテキスト対応のモードを選択することでより正確な結果を得られます。例えば、医療分野の専門論文を読み込ませて解釈させる、大規模なソースコードベースを渡してバグを検出させる、といった用途ではGPT-5 Proの力が発揮されるでしょう。逆に、軽い会話や創作文章のブレインストーミングであれば、GPT-5標準モードで十分高速かつ良質な応答が得られるでしょう。
また、コスト面の比較も重要です。GPT-5はAPI利用料金の面でも従来モデルより優位に設定されています。例えば、GPT-4(32kコンテキスト)のAPI料金が入力1Kトークンあたり$0.03、出力$0.06でしたが、GPT-5のAPIは入力$0.00125、出力$0.01と大幅に引き下げられています。これはGPT-4oの半分以下の価格であり、大規模なデータ処理を行う開発者にとってコスト負担が軽減される好材料です。GPT-5 Proについては、ChatGPT Proプランの月額料金(例えば$20程度)で利用できるため、個々の質問あたりのコストは非常に安く抑えられています。ただし、企業向けの高性能APIを利用する場合は高額になる可能性があるため、用途に応じて適切なモデルとプランを選択することが望まれます。
総じて、GPT-5およびGPT-5 Proの登場により、OpenAIは「より強力でより手頃なAIモデル」を提供することに成功しました。従来は高度なモデルほど高価格や長い応答待ち時間が伴っていましたが、GPT-5ではそのバランスが大きく改善されています。これにより、AIを活用したアプリケーション開発やサービス提供の裾野が一層広がり、今後ますます多くの領域でGPT-5ベースのAIが活用されていくでしょう。
ChatGPTの新機能:Apps SDKとマルチモーダル対応
DevDay 2025では、ChatGPT自体の機能拡張に関する重要な発表も行われました。その中心にあるのが、ChatGPT内で外部サービスやツールを連携させて動作する「Apps(アプリ)」機能と、その開発基盤となる「Apps SDK」です。また、ChatGPTがテキストだけでなく画像や音声といったマルチモーダルな入出力に対応しつつある点も注目すべき進化です。ここでは、ChatGPTの新機能について詳しく解説します。
ChatGPT内で動作する「Apps」とは
ChatGPT内で動作するアプリ(Apps)とは、ChatGPTのチャット画面上で直接他のサービスやツールを起動・利用できる仕組みです。例えば、ユーザーがChatGPTに「次の週末に東京で予算1万円以下のホテルを探して」と依頼すると、ChatGPTが内部で旅行予約サイトのアプリを呼び出し、条件に合致するホテル情報を検索・表示してくれる、といった使われ方を想定しています。このように、ChatGPTがエージェント的な役割を果たし、複数の外部アプリケーションを連携させてユーザーの要求に応えることが可能になります。
DevDay 2025の発表によれば、すでにSpotify(音楽ストリーミング)、Zillow(不動産検索)、Canva(デザインツール)といった主要サービスがChatGPT向けにアプリを提供し始めています。例えば、Spotifyアプリを利用すれば「○○というジャンルのリラックスできる曲を再生して」とChatGPTに頼むだけで、Spotify上で該当するプレイリストを再生できます。Zillowアプリなら「ニューヨークで賃貸の一戸建てを探して」と依頼すると、ChatGPTがZillowから該当する物件情報を取得して表示してくれます。Canvaアプリなら「犬の散歩のポスターを作って」と指示すると、ChatGPTがCanva上でデザインを作成し、そのプレビューをチャット画面に表示する、といった具合です。これらのアプリはChatGPTのプラグイン機能の進化版とも言え、よりシームレスで対話的に外部サービスを操作できる点が特徴です。
ChatGPTのApps機能は、プラグインの概念を拡張したものです。従来のChatGPTプラグインでは、ユーザーが明示的にプラグインを有効化してから特定のコマンドを与える必要がありました。しかしAppsでは、ChatGPTがユーザーの発話内容から自動的に適切なアプリを選択・起動します。例えば、「今日の天気は?」と尋ねれば天気予報アプリを呼び出し、「この文章をフランス語に翻訳して」と依頼すれば翻訳アプリを呼び出す、といった具合です。このコンテキストに応じた自動アプリ起動により、ユーザーはプラグイン名を覚えたり切り替えたりする手間なく、シンプルな会話だけで様々なサービスを利用できるようになります。
Apps SDKの仕組みと開発者への影響
ChatGPT Appsを実現するため、OpenAIは「Apps SDK」という開発キットを提供します。Apps SDKは、開発者が自社サービスをChatGPTに統合するためのフレームワークであり、モデルコンテキストプロトコル(MCP)と呼ばれる標準仕様に基づいています。MCPはChatGPTが外部ツールやデータに接続するためのオープンな仕様であり、Apps SDKはそれを拡張して対話型アプリの構築を容易にするものです。
Apps SDKを用いることで、開発者はChatGPT内で動作する独自アプリを作成できます。具体的には、ChatGPTと外部サービス間の通信や認証、データのやり取りをSDKが担うため、開発者は自社サービスの機能をChatGPTから呼び出せるように実装するだけで済みます。Apps SDKには、ユーザーからの指示を受けて外部APIを叩く「ツール」の定義方法や、ChatGPTに表示するカスタムUIコンポーネント(例えば地図やグラフなど)の作成方法、対話のコンテキストを保持する状態管理の仕組みなどが含まれています。これにより、開発者はChatGPT上で動作するインタラクティブなアプリケーションを構築でき、ユーザーはチャット画面内でそれらアプリを使ってタスクを完了できます。
Apps SDKの提供により、ChatGPTエコシステムはプラットフォーム化が進みます。従来、ChatGPTは単体のAIアシスタントとして機能していましたが、今後は各種サービスがChatGPTにプラグイン(アプリ)として組み込まれることで、ChatGPT自体が「AIベースの統合プラットフォーム」になっていくと考えられます。これはユーザーにとっても開発者にとってもメリットが大きいです。ユーザーにとっては、複数のサービスを行き来することなくChatGPT一つで様々なことができるため利便性が向上します。開発者にとっては、ChatGPTの膨大なユーザー基盤に自社サービスをアクセスさせることができるチャネルが開けるため、新たなビジネスチャンスとなります。
また、Apps SDKはオープンな標準であるMCPに基づいているため、OpenAI以外のAIチャットボットでも同様の仕組みを採用する可能性があります。これにより、将来的には異なるAIアシスタント間でアプリが互換性を持ち、開発者は一度実装すれば複数のプラットフォームで利用できるようになるかもしれません。このように、Apps SDKはAI時代のモバイルアプリストアのような存在を目指すものであり、AIエコシステムの発展に大きな影響を与えるでしょう。
ChatGPTのマルチモーダル対応と今後の展望
ChatGPTは当初テキスト入出力のみの対話AIでしたが、近年はマルチモーダル(複数モード)への対応が進んでいます。DevDay 2025でも、ChatGPTがテキストだけでなく画像や音声といったモードを扱えるようになってきたことが強調されました。
まず画像入力については、既に2023年にChatGPTに画像をアップロードして解析・説明させる機能が導入されています(一部ユーザーに限定)。これにより、ユーザーは写真や図表を渡して「この写真に写っている問題を解いて」「このグラフの内容を説明して」といった指示を出すことが可能です。DevDay 2025では、この画像理解能力がさらに向上し、より高精度に画像内の物体やシーン、テキストを認識できるようになったと報告されています。また、画像生成についても、ChatGPT内でテキストから画像を生成する機能が提供されています。OpenAIの画像生成モデル(DALL-E 3など)と連携し、ユーザーが文章でイラストの内容を指示するとChatGPTが画像を生成して表示してくれます。例えば「夕焼けの海辺に犬が走るイラストを描いて」と頼むと、それに沿った画像が生成されます。この画像生成機能もマルチモーダル対応の一環であり、ユーザーはテキストだけでなく視覚情報も扱えるようになりました。
次に音声対話です。ChatGPTは2023年に音声入力と音声出力に対応し、ユーザーはスマートフォンのマイクで話しかけ、ChatGPTが音声で答えてくれる機能が追加されました。DevDay 2025では、この音声対話の品質と応答速度がさらに改善されました。特筆すべきは、OpenAIが新たな音声モデル「gpt-realtime mini」を発表したことです。これは音声認識と音声合成を組み合わせたリアルタイム音声対話用の軽量モデルで、従来の高度な音声モデルに比べ70%も低コストで、同等の音声品質と表現力を実現するとされています。このモデルにより、低遅延でスムーズな音声会話が可能となり、ChatGPTをスマートスピーカーや音声アシスタントのように使うシーンが増えるでしょう。実際、アルトマンCEOは「音声は急速にAIとの主要なインタラクション手段の一つになりつつあり、将来的には不可欠になる」と述べており、ChatGPTの音声対話機能強化はその方針を反映したものです。
さらに、ChatGPTのマルチモーダル化は動画やその他のモードにも広がりつつあります。今回発表された動画生成モデル「Sora 2」は、将来的にChatGPTと連携してユーザーの指示から動画を生成・表示できる可能性があります。例えば、「この物語を短いアニメ動画にして」と依頼するとChatGPTがSora 2を使って動画を作成する、といった使われ方も考えられます。もっとも、動画生成は計算負荷が高いため、当面は専用のAPIやアプリケーションで提供されるでしょうが、長期的にはChatGPTの機能の一部として組み込まれる可能性があります。
マルチモーダル対応が進むことで、ChatGPTはより人間らしい対話相手へと近づいています。人間は会話の際、言葉だけでなく表情や声のトーン、周囲の状況(画像や動画)を用いて情報を伝達・理解します。ChatGPTもテキスト以外のモードに対応することで、より文脈豊かで直感的なコミュニケーションが可能になります。例えば、ユーザーが写真を見せながら「ここの修理にはどれくらい費用がかかるでしょう?」と質問すれば、ChatGPTは画像を解析して具体的な回答を返すことができます。また、音声で話しかけることで手が塞がっている状況でも情報を得られ、車での移動中など様々なシーンでAIアシスタントを活用できます。
今後、ChatGPTのマルチモーダル機能はさらに拡張されると予想されます。例えば、リアルタイムのビデオ通話中に相手の表情やジェスチャーを解析して会話をサポートする、ARグラスで見える映像をリアルタイムに説明する、といった高度なユースケースも考えられます。OpenAIは「あらゆるモードで人々をサポートする汎用AI」を目指しており、マルチモーダル対応はその実現に向けた重要なステップです。
音声対話とマルチモーダル機能の強化
前章でも触れましたが、DevDay 2025では音声対話およびマルチモーダル機能の強化が大きなテーマの一つでした。OpenAIは「AIとのインタラクションはテキストから音声へシフトしている」との認識のもと、音声対話の品質向上とコスト低減に注力しました。また、テキスト・画像・音声・動画といった様々なモードを統合的に扱う能力を高めることで、より自然で包括的なAIアシスタントへの進化を図っています。ここでは、音声対話とマルチモーダル機能の具体的な強化点を解説します。
音声対話モデルのアップデート
ChatGPTの音声対話機能は、音声認識(スピーチ-to-テキスト)と音声合成(テキスト-to-スピーチ)の両方を備えています。DevDay 2025では、この音声対話のバックエンドとなるモデルがアップデートされ、より高品質でリアルタイム性の高い音声対話が可能になりました。特に注目すべきは、OpenAIが発表した新モデル「gpt-realtime mini」です。これは音声認識と音声合成を組み合わせた軽量モデルで、従来の高度な音声モデルに比べ大幅に計算コストを削減しつつ、同等の音声品質と表現力を実現するものです。
gpt-realtime miniの特徴は、低遅延でリアルタイムなストリーミング音声応答が可能な点です。従来、ChatGPTが音声で答える際にはテキスト応答を生成してから音声合成するまでに若干のタイムラグがありました。しかし新モデルでは、テキスト生成と音声合成を並列的かつストリーミング的に行うことで、ユーザーが話し終えてすぐにAIが返事を始める、といったスムーズなやり取りが実現します。これにより、人間同士の会話に近いリアルタイム性が得られ、音声での対話がより自然に感じられるようになります。
また、gpt-realtime miniはコスト効率にも優れています。OpenAIによれば、このモデルは従来の高度な音声モデルに比べ70%も低コストで動作するとのことです。これはAPI利用料金の大幅な引き下げを意味し、開発者が自社アプリにChatGPTの音声対話機能を組み込む際のハードルを下げます。結果として、スマートスピーカーやカーナビ、コールセンターの自動応答システムなど、音声AIを活用したサービスの普及が加速するでしょう。
音声合成の品質についても向上が図られています。ChatGPTの音声はすでに自然な抑揚や感情表現が可能でしたが、新モデルではさらに人間らしい声質や表現のバリエーションが増えています。例えば、緊急を要するメッセージであれば緊張感のあるトーンで伝え、冗談を言う際には軽妙な口調にする、といった細かなニュアンスも再現できるようになっています。これにより、ユーザーは音声で話しかける際にもより人間らしい対話相手と感じることができるでしょう。
音声認識(音声からテキストへの変換)の精度も向上しています。特に雑音の多い環境や、アクセントのある話し方に対する耐性が強まり、ユーザーの発話内容をより正確に文字起こしできます。また、リアルタイム性を活かして途中で話しを中断する(インタラプト)ことも可能になりつつあります。例えば、ChatGPTが長い答えをしている最中でも、ユーザーが「ちょっと待って」と割り込めば即座に応答を停止し、新たな指示を受け付ける、といった対話の柔軟性が高まっています。
このように、音声対話モデルの強化により、ChatGPTはより身近で使いやすい音声アシスタントとなりました。今後、スマートフォンやスマートホーム機器にChatGPTの音声機能が組み込まれることで、日常的に話しかけて使うAIが一般化する可能性があります。OpenAIは音声を「AI利用の主要手段の一つ」と位置付けており、今後も音声対話の技術開発を重視していくとみられます。
マルチモーダル機能の拡張
マルチモーダル機能とは、テキスト・画像・音声・動画など複数の情報モードを統合的に扱う能力です。ChatGPTは近年、画像入力や音声対話に対応することでマルチモーダル化を進めてきましたが、DevDay 2025ではその範囲がさらに広がりました。
まず、画像の理解と生成です。ChatGPTは画像を入力として受け取り、その内容を説明したり解析したりできます。例えば、風景写真を渡せば「青い空と緑の丘が広がる風光明媚な写真です」といった描写を返し、表形式の画像を渡せば表の内容を読み取って解説してくれます。DevDay 2025では、この画像理解の精度が向上し、より細かな要素(写真中の文字や小さな物体)も認識できるようになりました。また、画像生成についても、よりクオリティの高い画像を生成できるようモデルが改良されています。ユーザーが与えるテキスト指示に沿って、より写実的で細部にこだわったイラストや写真風画像を作成できるようになりました。
次に、動画です。DevDay 2025で公開された動画生成モデル「Sora 2」は、テキストから短い動画を生成できる次世代AIです。Sora 2は高度な映像生成と音声生成を組み合わせており、例えば「夕焼けの海辺で子犬が飛び跳ねる10秒の動画」という指示に対し、それに見合う映像と効果音・環境音を自動生成します。この技術は現在API経由で開発者向けに提供され始めており、将来的にChatGPTと連携してユーザーが直接動画を生成できるようになる可能性があります。例えば、ユーザーがChatGPTに物語を書かせ、続けて「これを短編アニメにして」と依頼すれば、ChatGPTがシーン毎に動画クリップを生成して繋ぎ合わせる、といった高度なユースケースも考えられます。もっとも、動画生成は計算資源を大量に消費するため、現時点ではプレビュー提供段階ですが、その完成度は非常に高く注目を集めています。
また、その他のモーダルとして、音声以外のオーディオ(例えば環境音や音楽)の生成・編集にもAIが活用されています。OpenAIは音声合成技術を発展させ、単なる会話音声だけでなく音楽の作曲や効果音の生成にも応用できる研究を進めています。これにより、将来的にChatGPTがユーザーの指示でBGMを作ったり、録音した音声からノイズを除去したりといったことも可能になるでしょう。
マルチモーダル機能の拡張により、ChatGPTはあらゆる形態の情報を扱える汎用AIへと近づいています。人間はテキストだけでなく視覚や聴覚を通じて情報を得ていますが、AIもそれらを統合的に扱うことでより人間らしい理解と応答が可能になります。例えば、製品の説明をテキストで聞くだけでなく、ChatGPTが関連する写真や図表を表示しながら説明してくれれば理解が深まりますし、動画でプロセスを見せてくれればさらに具体的です。音声で話しかけることで手が塞がっている状況でも情報収集でき、マルチモーダルAIは日常生活のあらゆる場面で役立つでしょう。
OpenAIは「モデルがテキストや画像を理解し、音声で応答し、ツールを使いこなす」ことで「あらゆるモードで人々をサポートする汎用AI」を目指していると述べています。DevDay 2025の発表は、その目標に向けた大きな一歩であり、今後さらなるモーダル(例えば触覚情報やAR空間との連携など)への拡張も考えられます。マルチモーダルAIの進歩は、単なる技術革新に留まらず、人々の生活や仕事の在り方を変える可能性があります。ChatGPTのようなマルチモーダルAIが広く普及すれば、コミュニケーションの質が向上し、教育・医療・ビジネスなど様々な領域で新たな価値が生まれるでしょう。
開発者向けツールとAPIの改善
DevDay 2025では、開発者コミュニティへの取り組みも大きく強化されました。OpenAIは今回、開発者がより容易に自社サービスにAIを組み込めるよう、新たなツールやAPIの改善を多数発表しました。特に注目すべきは、エージェント構築ツール「Agent Builder」の登場、APIの高速化と新モデル提供、そしてコード生成モデルの強化です。これらにより、開発者はより高度なAIアプリケーションを効率的に開発できるようになります。以下、それぞれの詳細を解説します。
Agent Builder(エージェント構築ツール)
OpenAIはDevDay 2025で、「Agent Builder」と呼ばれる新しい開発ツールを公開しました。Agent Builderは、ビジュアルなインターフェース上でAIエージェントを構築できるツールで、コーディングに不慣れなユーザーでも簡単にカスタムAIを作成できるよう設計されています。具体的には、ユーザーはウェブブラウザ上のGUIでエージェントの挙動を定義し、必要なツールや知識ベースを追加することで、目的に合わせたAIアシスタントを生成できます。
Agent Builderの特徴は、ドラッグ&ドロップでエージェントの動作フローを設計できる点です。例えば、ユーザーからの質問に応じてウェブ検索を行い、得られた情報を要約して回答するといった一連の処理を、事前に用意されたモジュール(検索モジュール、要約モジュール、回答生成モジュール等)を繋ぎ合わせて構築できます。各モジュールにはOpenAIのAPIや外部サービスとの接続設定を行えるため、エージェントにウェブ検索機能やデータベース照会機能などを持たせることも可能です。また、エージェントの振る舞いを細かく調整するためのシステムプロンプトやパラメータ設定もGUI上で行え、エージェントの性格や応答スタイルをカスタマイズできます。
Agent Builderにより、非プログラマーでもAIエージェントを作成できるようになる点は画期的です。これまで、ChatGPTのAPIを使って独自エージェントを作るにはプログラミングの知識が必要でしたが、Agent Builderではビジュアル操作のみでエージェントを構築できるため、ビジネスユーザーやデザイナーなど幅広い層がAIを活用できるようになります。例えば、小売店の従業員が自社商品カタログに特化した問い合わせ対応エージェントを作成したり、教育現場で生徒向けの個別指導AIを作成したりといったことが容易になるでしょう。
また、Agent Builderは既存のChatGPTエコシステムとの親和性も高いです。生成したエージェントはChatGPTのインターフェース上で動作させることもでき、他のユーザーと共有して利用させることも可能です。OpenAIは今後、Agent Builderで作成したエージェントを公開・共有するためのプラットフォーム(いわゆる「エージェントストア」)を検討しているとも言われています。もしそれが実現すれば、開発者は自社サービス専用のAIエージェントを公開し、ユーザーは必要なエージェントをChatGPT上で呼び出して使う、といった新しいエコシステムが形成される可能性があります。
総じて、Agent Builderは「AI時代のNo-Code開発ツール」と位置付けられ、AI技術の民主化に寄与するものです。OpenAIは「開発者と企業がビジュアルUIで強力なAIエージェントを構築できるようにする」と述べており、このツールによってAI活用の裾野がさらに広がることが期待されます。
APIの改善と新モデルの提供
DevDay 2025では、OpenAIのAPIサービスにも多くの改善が行われました。開発者にとって、APIの高速化や新機能の追加は直接的な恩恵となるため、注目度が高かった領域です。
まず、応答速度の向上です。OpenAIはAPIエンドポイントの最適化を進め、モデルからの応答生成をより高速に返せるようにしました。特にGPT-5系モデルのAPIでは、従来のGPT-4系より応答がスピーディになったと報告されています。これはモデル自体の効率化に加え、OpenAIがクラウドインフラを拡張した効果もあります。例えば、大量のリクエストが同時に来ても待ち時間が短縮され、リアルタイム性が求められるアプリケーション(チャットボットや音声対話システムなど)でも安定した応答が得られます。
次に、新モデルのAPI提供です。DevDayで発表されたGPT-5やGPT-5 Pro、そして音声モデルgpt-realtime mini、動画モデルSora 2など、最新モデルはすべてAPIで利用可能になりました。これにより、開発者は自社アプリに最新AI機能を組み込むことができます。例えば、GPT-5 APIを使えば従来より高度なテキスト生成・要約・翻訳が可能になり、gpt-realtime mini APIを使えばリアルタイム音声対話機能を実装できます。また、Sora 2 APIを使えばテキストから動画を生成するサービスを提供できるようになります。OpenAIは今回、「開発者がSora 2と同じモデルを自分のアプリ内で利用できる」と述べており、これはコンテンツ制作系アプリや広告業界などに大きなインパクトを与えるでしょう。
さらに、APIの使い勝手向上も図られました。OpenAIはこれまで、モデルの選択やパラメータ設定が複雑だとの指摘もありましたが、DevDayではよりシンプルで統一的なAPI設計を提案しています。例えば、テキスト生成系モデルは共通のエンドポイントで呼び出し、内部で最適なモデルを選択する、といった仕組みです。これにより、開発者はモデルごとの細かな違いを意識せずに済み、シンプルなコードで最新モデルの機能を利用できます。また、機能呼び出し(Function Calling)の機能も安定化されており、ChatGPTが特定の関数を呼び出して結果を回答に組み込むといった高度な使い方がより容易になりました。これはツール使用型のエージェントを構築する上で重要な機能であり、今回の改善により開発者はより信頼性高くAIエージェントを実装できます。
加えて、コンテキスト管理の強化もAPIに導入されました。長大なコンテキストを扱う際の最適化や、ユーザーごとの会話履歴管理を助ける仕組みが提供され、開発者はユーザーの長い対話をよりスムーズに扱えるようになります。例えば、APIからセッションIDを指定して会話を継続させる機能や、過去の会話から重要な情報のみを抜粋して次のプロンプトに添付する(要約によるコンテキスト圧縮)機能などが試験導入されています。
総じて、OpenAI APIはDevDay 2025を機により高速・高度・使いやすいものへと進化しました。これにより、開発者はAIを活用した新サービスをより短期間で開発・展開できるようになります。実際、OpenAIは「開発者がより速くコードを書き、より信頼性高くエージェントを構築し、ChatGPT上でアプリをスケールさせられるよう次世代のツールとモデルを導入した」と述べており、開発者コミュニティへのコミットメントを示しています。
コード生成と開発支援の強化
DevDay 2025では、ソフトウェア開発者を支援するAI機能にもアップデートがありました。OpenAIはこれまで、プログラミング向けのモデル「Codex」を提供してきましたが、今回その後継とも言える「Codium」というコード生成モデルがChatGPT内で利用可能になりました。CodiumはCodexの改良版であり、より高度なコード補完やソースコードの理解・生成が可能です。
CodiumをChatGPTに組み込むことで、ユーザーはチャット画面上でプログラミングの質問に答えさせたり、コードを生成・デバッグさせたりできます。例えば、「Pythonで二分探索のアルゴリズムを書いて」と依頼すればChatGPTが適切なコードを生成し、「このコードのバグを見つけて」と尋ねれば問題点を指摘して修正提案をしてくれます。Codiumは大規模なコードベースの理解にも優れており、数百行に及ぶプログラムを渡して「この関数の役割を説明して」と聞けば、その機能や依存関係を解説してくれます。
また、OpenAIは開発者向けのプラグインや統合機能も強化しました。例えば、Visual Studio Codeなどの開発環境にChatGPTを組み込む拡張機能が提供され、エディタ上で直接ChatGPTにコードの質問を投げたり、関数のドキュメントを自動生成させたりできるようになります。これにより、ソフトウェア開発の各段階(設計、コーディング、テスト、デバッグ)でAIが支援し、生産性を高めることが期待できます。
さらに、ペアプログラミングAIとしてのChatGPTの能力も向上しました。ユーザーがコードを書いている途中で「次に何をすべきか」と相談すれば、ChatGPTがアルゴリズムの提案やコードスニペットを提示してくれます。また、既存のコードに対してリファクタリングの提案をしたり、セキュリティ上の問題点を指摘したりと、経験豊富なペアプログラマーのように振る舞います。実際、GPT-5系モデルはコード生成の精度が飛躍的に向上しており、SWE-benchというベンチマークではGPT-5(Thinkingモード)が74.9%という高い正答率を記録し、従来のGPT-4oの30.8%を大きく上回りました。これは複雑なコード修正タスクにおいても、GPT-5がかなりの正解を導けることを示しており、プログラマーの生産性向上に大きく寄与するでしょう。
総じて、DevDay 2025の発表により「AIによるソフトウェア開発支援」は一層進化しました。ChatGPTがコーディングのパートナーとして機能し、開発者はより少ない労力でより良いコードを書けるようになります。これはソフトウェア産業全体の効率化につながり、新しいアプリケーションやサービスの開発サイクルを短縮する可能性があります。もっとも、AIが生成したコードをそのまま信頼せず、開発者自身が検証する姿勢は引き続き重要です。しかし、AIがルーチン作業を肩代わりしてくれることで、開発者は創造的な部分により多くの時間を割けるようになるでしょう。
OpenAIとAMDの提携によるインフラ強化
DevDay 2025では、AIモデルやソフトウェアの発表だけでなく、インフラ面での大きな発表も行われました。それは、OpenAIが半導体大手AMD社と戦略的提携を結び、AI計算資源の供給を確保するというものです。この提携は、OpenAIが今後のモデル開発やサービス拡大に必要な膨大な計算パワーを確保し、技術競争で優位を保つための重要な一手と言えます。以下、提携の内容と背景、そして業界への影響について解説します。
提携の内容と目的
OpenAIとAMDの提携により、OpenAIはAMDから多数のAIチップ(GPU)を供給されることになります。具体的には、今後数年間で合計6ギガワット分のAIチップをAMDの「Instinct」シリーズGPUとして受け取る計画です。6ギガワットとは非常に大きな電力であり、それに見合う膨大な数のGPUが供給されることを意味します。これは、OpenAIがこれまで主に依存してきたNVIDIA社製GPU以外にも、AMD製の計算資源を活用できるようになることを示しています。
また、提携には株式関係の取り決めも含まれています。AMDはOpenAIに対し、自社株式の最大10%を1株あたり1セント(0.01ドル)という象徴的な価格で取得できる権利(ワラント)を付与しました。これは非常に優遇された条件であり、OpenAIが将来AMDの株主となる可能性も示唆しています。逆に、AMDもOpenAIに対し将来的に最大10%の出資権を取得できる権利を与えられています。このように、両社は資本面でも結びつきを強めることで、長期的なパートナー関係を築く構えです。
この提携の目的は、OpenAIの計算インフラを多角化・強化することです。近年、AIモデルの訓練や運用には大量のGPU計算資源が必要であり、その大半をNVIDIAの製品が占めています。しかしNVIDIA製GPUは供給不足や高価格といった課題もあり、OpenAIも計算資源の制約に直面していました。AMDとの提携により、OpenAIはNVIDIA以外の供給源を確保でき、需要に応じて柔軟に計算リソースを拡張できるようになります。これはモデル開発のスピードアップや、サービス品質の向上(レスポンスの高速化や同時接続数の増加)につながるでしょう。
また、AMDにとってもこの提携は大きなメリットがあります。OpenAIのような最先端AI企業が自社GPUを採用することで、AMD製AIチップの信頼性や性能が証明されることになります。これは他の企業への販売促進にもつながり、AIチップ市場でのシェア拡大に寄与します。実際、提携発表後、AMDの株価は一時34%以上急騰し投資家の期待を集めました。これは、市場がこの提携を「AMDがAIインフラ分野で本格参入する」と評価したためです。
提携の背景と業界への影響
OpenAIがAMDと提携する背景には、AIチップ市場の寡占化への対抗と自社インフラの安定確保があります。現状、高性能AI計算用のGPUはNVIDIAが事実上独占状態にあり、他社(AMDやGoogleのTPUなど)は追随を図っていますがまだ市場シェアは限定的です。OpenAIはマイクロソフトとの提携によりAzureクラウド上のNVIDIA GPUを大量に利用してきましたが、今後もモデルをスケールさせていくには供給面のリスクがあります。AMDとの契約により、そのリスクを分散できるのです。
また、OpenAIはAGI(汎用人工知能)の実現を長期目標と掲げており、そのためには今以上の計算資源が必要と考えられます。AMDのInstinct GPUは最新のHBMメモリや高速インターコネクトを搭載しており、大規模モデル訓練に適したアーキテクチャを備えています。OpenAIはAMDの技術力を評価し、将来的なモデル(GPT-6やそれ以降)の訓練にもAMD製チップを活用できる可能性があります。これは、AI研究における計算基盤の多様化を促し、技術進歩の加速につながるでしょう。
業界全体への影響としては、AIチップ市場の競争激化が挙げられます。NVIDIA一強だった市場に、AMDがOpenAIという重量級顧客を獲得したことで、他のクラウド事業者やAI企業もAMD製GPUを検討するようになるかもしれません。これは市場競争を促し、結果的に価格低下や技術革新が進むと期待できます。また、OpenAIが複数のチップセットを用いてモデルを最適化することで、クロスプラットフォームで動作する効率的なAI実装が生まれる可能性もあります。これはオープンソースコミュニティや他社にも波及し、AI技術の民主化に寄与するでしょう。
さらに、この提携は米国政府や規制当局の注目も集めています。AI技術の発展は軍事・安全保障上も重要であり、計算資源の確保は国家戦略的課題となっています。OpenAIとAMDの提携は、米国企業同士が協力してAIインフラを強化する好例として評価される一方、中国など他国勢力に対する優位性確保の意味合いもあります。今後、政府がこうした民間提携を支援したり、逆に独占規制の観点から見守ったりする可能性もあります。
総じて、OpenAIとAMDの提携は「AIインフラの裏側」に大きな変化をもたらす出来事です。ユーザーから見えない部分ですが、計算資源の拡充はChatGPTや他のAIサービスの性能向上や安定提供に直結します。今後、OpenAIがどのようにAMD製チップを活用してモデルを訓練・運用していくのか、そして競合他社(例えばGoogleやMeta)がどのように対抗するのか、業界の動向が注目されます。
Sora 2によるテキストから動画生成の新時代
DevDay 2025では、テキストから動画を生成する次世代モデル「Sora 2」の登場も大きな話題となりました。Sora 2はOpenAIが開発した高度な動画生成AIで、テキストの指示に基づいて写真のようにリアルな映像を自動生成できます。さらに、映像と同期した音声(効果音や環境音)も同時に生成できる点が特徴で、これにより完全にAIが制作した短編動画を手軽に作れるようになります。ここでは、Sora 2の特徴や改良点、そしてその活用例や業界へのインパクトについて詳しく見ていきます。
Sora 2の特徴と改良点
Sora 2は、OpenAIが2024年に公開した動画生成モデル「Sora」の後継として位置付けられます。Sora自体が当時大きな注目を集めましたが、Sora 2ではその性能が飛躍的に向上しています。主な特徴は以下の通りです。
- 写実的で物理的に整合性の高い映像:Sora 2は生成する映像のリアリティが非常に高く、物体の動きや光の挙動など物理的な整合性も保たれています。例えば、「バスケットボールがリングに入らずバックボードに当たる」といったシーンでも、Sora 2はボールが正しく跳ね返る様子を描写します。従来の動画生成AIでは物理法則に反する挙動(例えばボールが宙に消える等)がしばしば見られましたが、Sora 2ではそうした不自然さが大幅に減少しています。
- 音声との高度な同期:Sora 2の最大の革新点は、生成される動画に音声(オーディオ)が自動的に付与されることです。映像中の出来事に合わせて効果音や環境音が同期して生成され、シーンの臨場感が飛躍的に高まります。例えば、「雨の降る夜道を歩く人」という指示では、雨粒の音や足音が映像と一緒に生成されます。これにより、AI生成動画は「サイレント映画」から「トーキー(音声付き映画)」の時代へと進化しました。
- クリエイティブな制御と多様なスタイル:Sora 2はユーザーの細かな指示にも応えられ、カメラアングルや照明、映像のスタイル(写実、アニメ調、水彩画風など)を指定することも可能です。例えば「魚眼レンズのワイドショットで」「映画のような色調にして」といった追加指示を与えると、それに沿った映像表現が実現します。これにより、ユーザーは自分のイメージ通りの映像をAIに生成させることがより容易になりました。
- 短いが高品質な動画生成:現時点でSora 2が生成できる動画の長さは数秒~十数秒程度と短めですが、その品質は非常に高く解像度も高いです。OpenAIはSora 2を「コンセプト開発のツール」と位置付けており、例えば広告の雰囲気を試すためのビジュアル案をすぐ作ったり、玩具デザイナーがスケッチから玩具の動きをイメージするための動画を作ったりといった用途を想定しています。短い映像でも十分に物語性や情報伝達が可能であり、そうした用途に最適化されています。
Sora 2の性能向上は、OpenAIのモデル訓練技術の進歩と計算資源の拡充によるものです。大規模な動画データセットでの訓練や、新たなアーキテクチャ(拡散モデルとトランスフォーマーの組み合わせなど)の導入により、これまで困難だった長手間の動画生成や音声同期が実現しました。また、OpenAIはSora 2を開発する際にマット・エルンの玩具メーカーMattel社と協業し、玩具開発プロセスへのAI活用にも取り組んでいます。このように、産業界との連携によってモデルの実用性を高めている点も特筆されます。
Sora 2の活用例と業界へのインパクト
Sora 2が登場したことで、動画コンテンツ制作の在り方が大きく変わりつつあります。従来、動画を作るにはカメラやスタッフ、時間が必要でしたが、Sora 2を使えばテキストを入力するだけで短い動画クリップを即座に生成できます。これは様々な分野で新たな可能性を開きます。
例えば、広告制作の現場では、商品のイメージを掴むためのティザー動画をSora 2で試作し、複数の案を素早く検討できます。従来なら脚本作成から撮影・編集まで数週間かかる作業が、AIによって数分で案を出せるため、クリエイティブプロセスが飛躍的に効率化されます。実際、アルトマンCEOも「商品の雰囲気に基づいて広告のビジュアル案を作る」例を挙げており、広告業界はSora 2の活用に大きな期待を寄せています。
また、ゲームやCG制作の分野でもSora 2は有用です。ゲームデザイナーはキャラクターの動きやシーンの雰囲気をテキストで記述し、AIに短い動画を生成させることで、コンセプトのビジュアル化を素早く行えます。これはストーリーボード作成の代替や補助として機能し、制作現場の意思疎通を円滑にするでしょう。さらに、玩具メーカーでは設計段階でAIに玩具の動きをシミュレートさせ、実際に試作品を作る前に動作や魅力を検討できます。Mattel社との協業例では、デザイナーのスケッチからAI動画を生成し、玩具の遊び方を視覚化する試みが行われています。
さらに、教育やエンターテインメントの領域でも応用が考えられます。例えば、歴史の授業で「ローマ帝国の街並みを歩く」といった動画をAI生成し、生徒に没入型の学習体験を提供する、といったことが可能になります。また、映画愛好家が自分で原作小説のシーンを動画化して楽しむ、といったユーザー生成コンテンツ(UGC)の新たな形態も登場するでしょう。実際、OpenAIはSora 2に合わせて「Soraアプリ」というTikTok風の動画共有アプリを公開しました。このアプリではユーザーが自分や友人の写真からキャラクターを作り、テキストでシナリオを書くとAIがそれに沿った短い動画を生成し、他ユーザーと共有できます。これは誰でもAI動画を作って楽しめるプラットフォームであり、動画版TikTokとも呼ばれています。Soraアプリの登場により、動画コンテンツの制作がより民主化され、新たなクリエイティブコミュニティが形成される可能性があります。
もっとも、Sora 2のような高度な動画生成AIが登場したことで、倫理的・社会的な課題も浮上します。例えば、偽の動画(ディープフェイク)を悪意ある目的で作られるリスクがあります。実際、Sora 2ではユーザー自身の写真を元にAIが人物を動画に登場させることも可能であり、誰もが簡単にディープフェイク動画を作れてしまいます。このため、OpenAIはSora 2の利用規約や技術的な対策(生成動画に不可視のウォーターマークを埋め込む等)を検討していると報じられています。また、クリエイターにとっても脅威となり得ます。動画制作がAIによって容易になることで、人間の映像クリエイターの役割はどう変わるのか、新たな価値創出の方向が模索されるでしょう。
業界全体としては、Sora 2の登場により「AIコンテンツ産業」が一気に発展したと言えます。映像編集ソフトメーカーやクラウド動画プラットフォームは、AI生成動画を取り込む新機能を急いで開発しています。また、映画産業でもAIを用いたプリビジョン制作や、俳優のデジタルダブル生成などへの活用が進んでいます。Sora 2はその先端に立つ技術であり、今後さらに長尺で高品質な動画生成が可能になれば、映像制作の在り方を根底から変える可能性があります。
コストと提供状況
現時点で、Sora 2はAPI経由で開発者向けにプレビュー提供が開始されています。一般ユーザーはまだ直接利用できませんが、前述のSoraアプリを通じて一部機能を試すことができます。API利用料金については、生成する動画の解像度や長さに応じて設定されており、高品質・長尺な動画ほど費用がかかる仕組みです。OpenAIはSora 2の計算コストが非常に高いため、利用には一定の制限があるとしています。ただし、需要に応じてインフラを拡充し、将来的により安価に提供できるよう努力すると述べています。
Sora 2の正式リリースや一般向けサービス開始時期は未定ですが、OpenAIは動画生成AIを次の重要な事業領域と位置付けているようです。テキスト・画像生成に続き動画生成を手掛けることで、OpenAIはマルチモーダルAIサービスのリーダーシップを維持しようとしています。競合他社(例えばGoogleやMeta)も動画生成技術を開発中であり、今後の技術競争は激化するでしょう。しかし、Sora 2が示した高い完成度は業界全体の底上げを促し、ユーザーにとってはより便利でクリエイティブなAIツールが次々登場することになるでしょう。
開発者コミュニティと今後の展望
DevDay 2025での一連の発表は、OpenAIが開発者コミュニティとの関係を一段と強化しようとする姿勢を示したものです。新しいモデルやツールの提供、APIの改善、そして企業提携によるインフラ拡充まで、あらゆる面で開発者がAIを活用しやすい環境づくりが図られました。ここでは、これら発表が開発者コミュニティに与える影響と、今後の展望について考察します。
開発者コミュニティへの影響
まず、DevDay 2025の発表により開発者に利用可能なAI技術の幅が飛躍的に広がったことが挙げられます。GPT-5やGPT-5 Proの登場で、より高度な自然言語処理が誰でも手軽に試せるようになりました。また、ChatGPT AppsやAgent Builderの提供により、プログラミングに詳しくないユーザーでもAIを組み込んだサービスを作れるようになりました。これはエントリーバリアの低下を意味し、新たな開発者やクリエイターがAI分野に参入しやすくなるでしょう。
特に、Apps SDKやAgent Builderはエコシステム形成を促すものです。開発者は自社サービスをChatGPTアプリとして提供したり、独自エージェントを公開したりすることで、OpenAIのプラットフォーム上でビジネスチャンスを得られます。これにより、OpenAI周辺には多様なサードパーティ製アプリやエージェントが生まれ、ユーザーにとってもより便利なChatGPT体験が提供されるでしょう。これはモバイルアプリストアのような循環をAI領域で再現するものであり、開発者コミュニティの活性化につながります。
また、APIの改善や新モデル提供は開発者の生産性向上に直結します。より高速で高精度なモデルを使えることで、アプリケーションの性能が向上し、ユーザー満足度が上がります。さらに、長大なコンテキストを扱えることで、これまで難しかった大規模データ分析や長期会話管理といった機能も実装可能になります。これらは新しいサービスアイデアの創出を促し、開発者コミュニティ内でのイノベーションを加速させるでしょう。
加えて、OpenAIとAMDの提携によるインフラ強化は、開発者が利用するAIサービスの安定性とコストにも良い影響を与えます。計算資源が増えればサービスのレスポンスが向上し、待ち時間が減ります。また、供給源の多様化によりGPU価格の高騰リスクが下がり、API利用料金の安定や低下も期待できます。これらは開発者にとって安心材料であり、より大胆なAIプロジェクトに挑戦しやすくなるでしょう。
もっとも、開発者コミュニティには新たな課題も生まれます。例えば、多数のモデルやツールが登場したことで選択の幅が広がった反面、どれを使えば良いか迷うケースもあるでしょう。OpenAIは公式ドキュメントやチュートリアルを充実させ、開発者が最適なツールを選べるようガイドする必要があります。また、ChatGPT Appsやエージェントの開発においては、セキュリティやプライバシーの問題にも注意が必要です。外部サービスと連携する以上、ユーザーデータの取り扱いや認証機構の実装など、開発者は新たな知識を身につける必要があるでしょう。
総じて、DevDay 2025は「開発者への贈り物」のようなイベントとなりました。OpenAIは自社の技術をブラックボックス化せず、開発者に広く開放して活用してもらおうとしています。これは開発者コミュニティから好評を博しており、実際DevDay後には「ChatGPTをもっと使いこなしたい」「自社サービスと統合してみたい」という声がSNS上で多数見られました。OpenAIが開発者を味方につけることで、自社エコシステムの拡大と強固なコミュニティ形成に成功すれば、競合他社に対する大きな優位性となるでしょう。
今後の展望
DevDay 2025で示された方向性から、OpenAIの今後の戦略をうかがうことができます。まず、モデルのさらなる進化です。GPT-5は現在最新ですが、OpenAIは既に次のモデル(GPT-6やそれ以降)の研究を続けていると考えられます。マルチモーダル性や推論能力、安全性といった点で一層の向上が図られるでしょう。特にAGIに近づくためには、より汎用的で自律的なAIが必要であり、そのための新しいアーキテクチャや学習方法の模が進むと予想されます。
次に、プラットフォーム化の深化です。ChatGPTはもはや単なるAIアシスタントではなく、アプリやエージェントが集積するプラットフォームへと変貌しつつあります。今後、OpenAIはChatGPT上で動作するサードパーティアプリのマーケットプレイスを構築したり、企業向けにカスタムエージェントを展開する仕組みを整備したりする可能性があります。また、ユーザーごとに好みのアプリやエージェントを組み合わせられる「パーソナルAI環境」を提供することも考えられます。これにより、ChatGPTは一人ひとりに最適化されたAIアシスタントとなり、より身近に使われる存在になるでしょう。
さらに、産業界への浸透も加速するでしょう。DevDayでは金融・医療・法律など各業界向けのAI活用が言及されましたが、今後はOpenAIが業界特化型のモデルやソリューションを提供する可能性があります。例えば、医療向けには医学文献や電子カルテを高度に理解できるモデル、金融向けには市場データをリアルタイム分析できるモデル、といった具合です。こうした専門モデルは汎用モデルに比べ精度や安全性が高められており、現場での実用に耐えるでしょう。OpenAIは既にMicrosoftや各種企業と提携していますが、今後は産業別にコンソーシアムを組んでデータを収集・学習し、業界特化AIを開発する動きも考えられます。
技術的な観点では、エネルギー効率と計算資源の最適化が引き続き重要なテーマです。モデルが巨大化するほど計算コストも増大しますが、AMDとの提携や新しいチップアーキテクチャの導入により、より効率的にAIを動かす技術が開発されるでしょう。また、オンデバイスAIの発展も見逃せません。スマートフォンやエッジデバイス上で一部のAI処理を行い、クラウドと協調するハイブリッド型サービスも今後登場する可能性があります。これにより、リアルタイム性が求められる応用(自動運転やロボティクスなど)にもAIが広がっていくでしょう。
最後に、倫理・社会的責任の面です。AI技術の発展が速まるほど、その影響を適切に管理することが重要になります。OpenAIは一貫して安全対策や誤用防止に取り組んでいますが、今後も透明性の確保や規制との協調が求められます。例えば、生成AIの出力にデジタル署名を付与して追跡可能にする、AIが関与したコンテンツにラベルを付ける、といった取り組みが業界標準となる可能性があります。また、AIによる雇用への影響や教育への活用など社会的課題にも対処していく必要があります。OpenAIはDevDayでも安全や倫理について触れており、今後もその姿勢を崩さずAIの良い方向への発展に努めるでしょう。
以上のように、DevDay 2025はOpenAIにとって画期的なイベントであり、AI業界に新たな潮流を生みました。より強力で使いやすいAIモデル、そしてそれを活用するための豊富なツール群が提供されることで、開発者コミュニティはこれまで以上にAIを駆使したイノベーションを起こすでしょう。OpenAIも開発者やパートナー企業と協力しながら、AGIへの道筋を模索し続けるでしょう。今後のAI技術の進展は目が離せませんが、DevDay 2025の発表はその出発点として大きな意義を持っています。
よろしければTwitterフォローしてください。
]]>










 投資ハイライト
投資ハイライト 企業概要:量子コンピューティングのパイオニア
企業概要:量子コンピューティングのパイオニア 最新技術:Advantage2システム
最新技術:Advantage2システム 量子アニーリング技術の革新
量子アニーリング技術の革新 3C分析:競争環境の徹底解剖
3C分析:競争環境の徹底解剖 Customer(顧客)
Customer(顧客) Company(自社)
Company(自社) Competitor(競合)
Competitor(競合) SWOT分析:戦略的ポジション評価
SWOT分析:戦略的ポジション評価 Strengths(強み)
Strengths(強み) Weaknesses(弱み)
Weaknesses(弱み) Threats(脅威)
Threats(脅威) ビジネスモデルと財務パフォーマンス
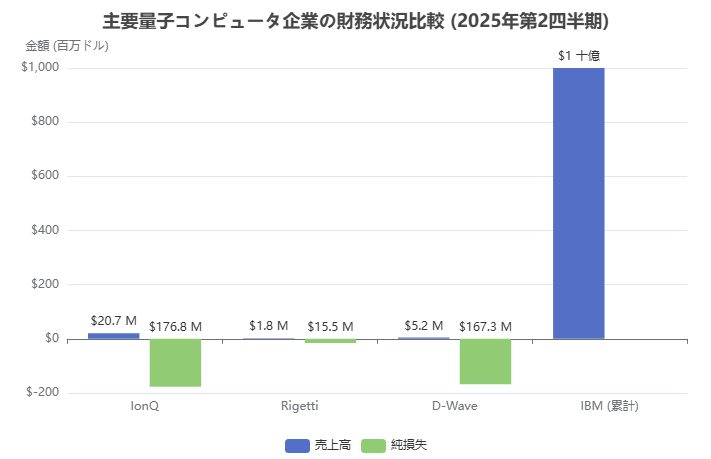
ビジネスモデルと財務パフォーマンス 2025年Q2財務ハイライト
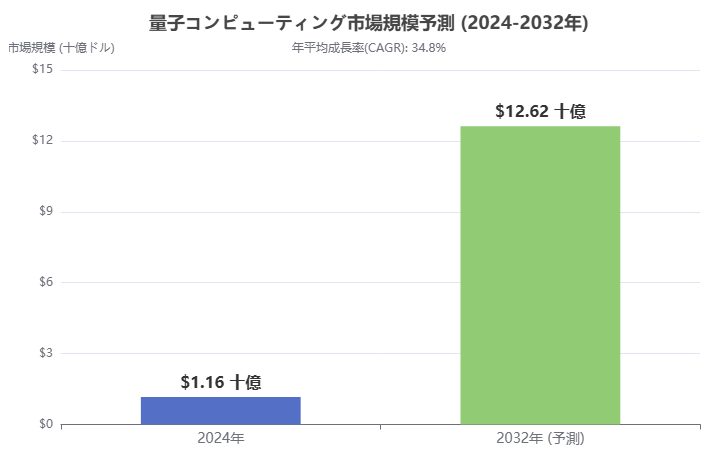
2025年Q2財務ハイライト 市場規模と成長予測
市場規模と成長予測 株価分析と将来予測
株価分析と将来予測 12ヶ月予想シナリオ
12ヶ月予想シナリオ 楽観シナリオ
楽観シナリオ 物流・サプライチェーン最適化
物流・サプライチェーン最適化 金融サービス
金融サービス ヘルスケア・創薬
ヘルスケア・創薬 AI・機械学習
AI・機械学習 競合分析:量子コンピューティング戦国時代
競合分析:量子コンピューティング戦国時代 IBM Quantum
IBM Quantum Google Quantum AI
Google Quantum AI IonQ
IonQ Rigetti Computing
Rigetti Computing 戦略的パートナーシップ
戦略的パートナーシップ 投資判断とまとめ
投資判断とまとめ